

What is binary diffing?
In the previous part we talked about both Windows patches and their format. Now that we have some understanding of how these patches are packaged we can discuss binary diffing in preparation for the final part in which we will diff a Windows patch. So let’s dive in.
What is binary diffing?
Binary diffing is a way to visualize and spot differences between two binaries. It presents us with a set of non-trivial challenges. Usually if you want to compare two files it’s more often than not if they are identical. If that’s the case you can just do a byte by byte comparison; this will however not suffice when it comes to binary diffing. One of the core challenges we need to solve is to be able to find the functions within the binary. This might sound like a trivial problem but if you take into account the challenges that come with indirect calls, virtual function tables, jump tables, exception handling and different calling conventions you quickly realize it might not be trivial, and in fact there is no perfect solution. [1]
On top of that we have to overcome the fact that functions might not reside on the same offsets within the file, functions might not have the same amount of basic blocks, basic blocks might have changed in size and instructions might have been removed/swapped/changed within the basic blocks.
As these tools parse the binary they collect features such as functions, CFG (Call Flow Graph) and function flow charts. In addition, there is detailed information collected on the basic blocks, their edges and what instructions they contain. In some cases binary diffing tools also make use of – or are incorporated into – other tools such as IDA Pro, [2] Ghidra, or Binaryninja. This gives easy access to a higher abstraction level with their respective intermediate languages and has the benefit of removing a lot of the low-level noise that doesn’t actually explain what the function is doing, such as stack operations, function prologue, and epilogue.
Here are some strategies that may be deployed: [3] [4]
- Function based hashing which matches identical functions
- Function name based hashing which matches the actual function names
- MD-index [5] – basically a “hash function” for CFGs in which the algorithm is based on the graph and in which the topological order and in- and out-degree are a part of the algorithm used to calculate a hash that can be easily matched. This algorithm is then used in multiple ways.
- Small prime product in which the matching is calculated by giving each mnemonic a corresponding prime number, and then all mnemonics are multiplied to give us a value that is independent from the position of each of the mnemonics.
- Matching back edges of loops using the Lengauer-Tarjan algorithm [6] – an algorithm used to quickly find dominators in a flowgraph.
- String references
- Constants used
- Call sequences
- Edge prime product in which the source and destination basic block prime product matches
This is in no way a comprehensive list, but it shows some of the strategies used and that it’s way more complex than a naive byte-by-byte comparison. It should also be noted that none of these techniques are relied on in isolation but are instead combined together to ultimately provide you with a sufficient confidence level in the matches it ends up with.
Are there any actual real-world uses?
Yes! There are multiple use cases where diffing binaries can be a valuable tool. These include purposes such as variant analysis, [7] vulnerability research, [8] patch validation [9] or perhaps you’ve identified a statically linked library and want to get symbols for it.
In malware analysis it’s a good way to get a quick start on a new version of a family you’ve previously reverse engineered. If you’ve already spent days reverse engineering a sample and all of a sudden a new version is released then the question becomes – what changed? Without binary diffing this is tedious manual work in which you are pretty much left trying to figure out which functions are the same before manually transferring function signatures, types and names to the new binary.
This is where binary diffing tools such as Diaphora and BinDiff really shine as they can provide you with an easy way to match the majority of functions and to transfer their names over to the new sample. You will also get a quick overview of what has changed and which functions were added/removed as well as some indication of the confidence of those matches.
In vulnerability research/red teaming it’s a good way to develop 1-days. If you want to show the impact of not keeping your system up to date, there is no better way to show the cost of not maintaining a decent patch management than owning the network.
Binary diffing also provides researchers with a hint of a module/system that contains vulnerabilities, and where there is one there might also be others. Or perhaps a patch was based on a bad root-cause analysis which in turn makes it possible to bypass the patch entirely.
What tools can we use?
BinDiff
We have multiple tools to choose from, but the most well-known of them is BinDiff – developed by Zynamics and Halvar Flake’s team and later bought by Google. Today it might not get new killer features all the time, but it’s been made available for both Ghidra [10] and Binaryninja, [11] It has been the unparalleled champion of binary diffing for years, and became the industry standard.
BinDiff is a comparison tool for binary files, that assists vulnerability researchers and engineers to quickly find differences and similarities in disassembled code.
With BinDiff you can identify and isolate fixes for vulnerabilities in vendor-supplied patches. You can also port symbols and comments between disassemblies of multiple versions of the same binary or use BinDiff to gather evidence for code theft or patent infringement. [12]
Bindiff comes with its own UI where we can create a new workspace and select two idb/i64 files we want to compare:
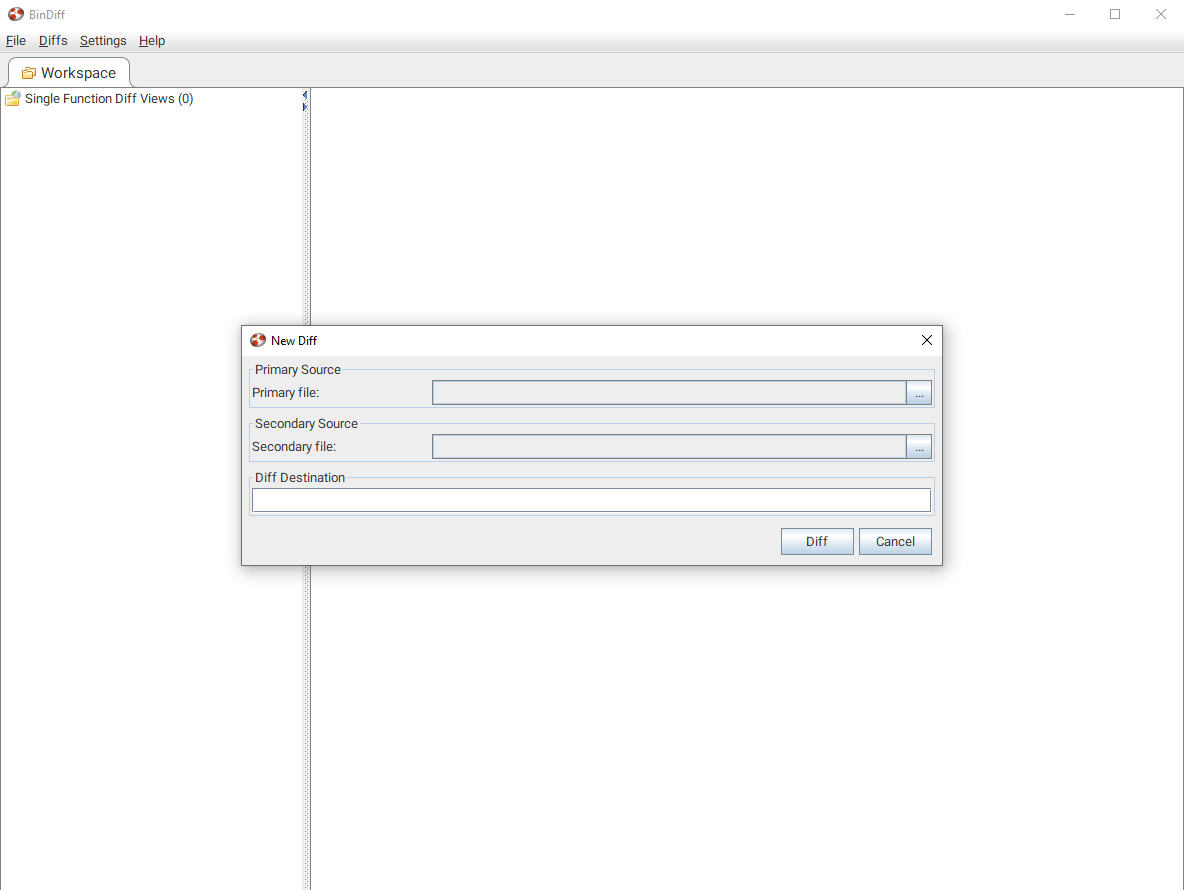
We are then presented with this screen where we get an overview of what changed:
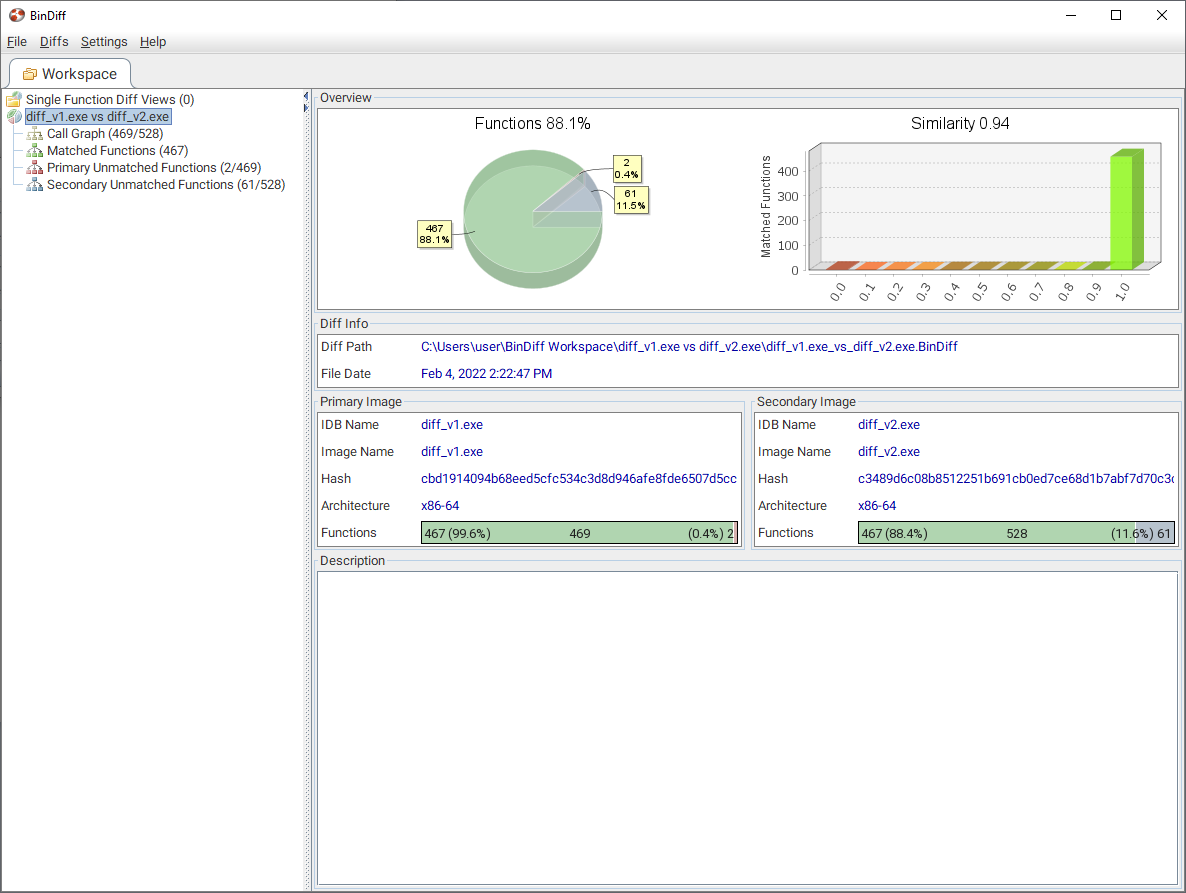
We can then pick and compare a function directly in their UI. This is also accessible from the context menu inside of IDA.
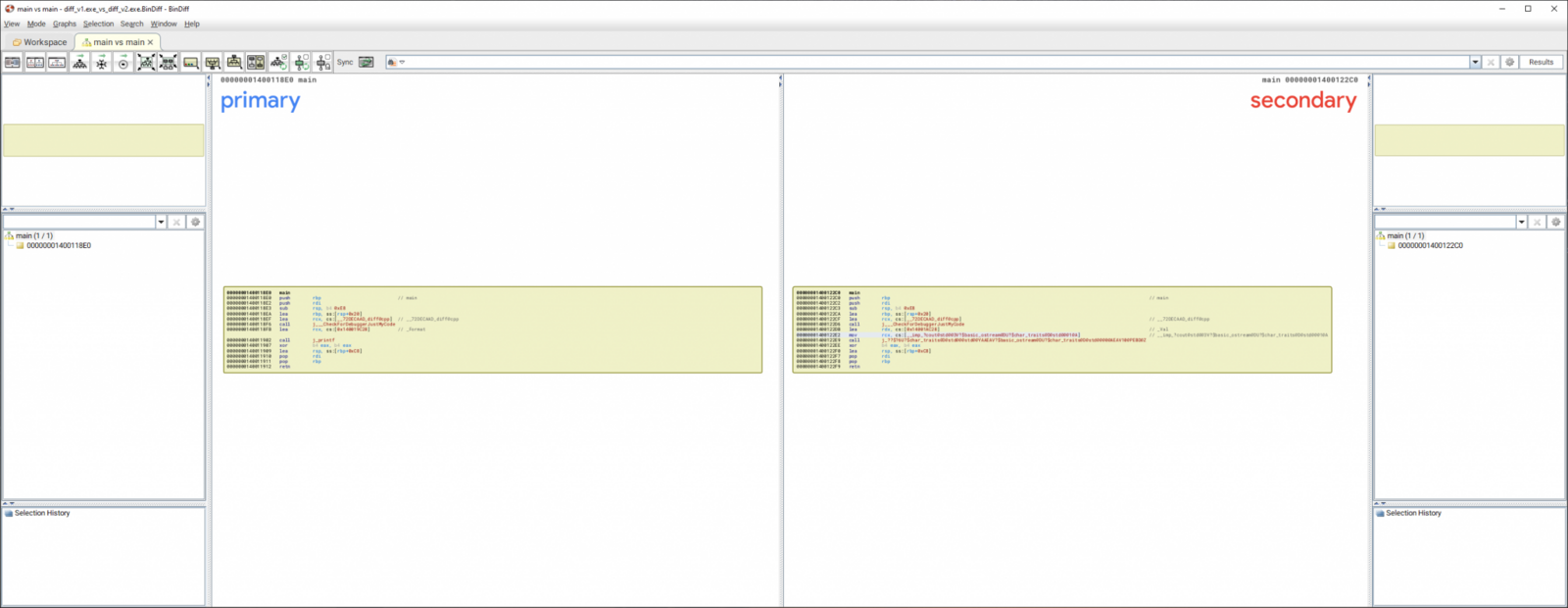
Inside of IDA we have the following where we can diff a database or just load previous results:
As the results are presented we get a number of tabs which give you some statistics. The Primary Unmatched tab shows functions that exist in the currently opened IDB that were not found in the other file, while the Secondary Unmatched and Matched Functions tabs should be self-explanatory.

As we can see, the Matched Function tab also provides us with a measurement on the similarities as well as the confidence of the match, the algorithm that was used and the names of the respective files. From the context menu we can now import symbols.
Diaphora
We also have Diaphora, which is being actively developed and maintained and has both new features added as well as additional features planned for the future.
It also has some really interesting features such as:
- Parallel diffing
- Pseudo-code based heuristics
- Pseudo-code patches generation
- Ability to port structs, enums and typedefs
- Diffing pseudo-codes (with syntax highlighting!)
- Scripting support (for both the exporting and diffing processes) [13]
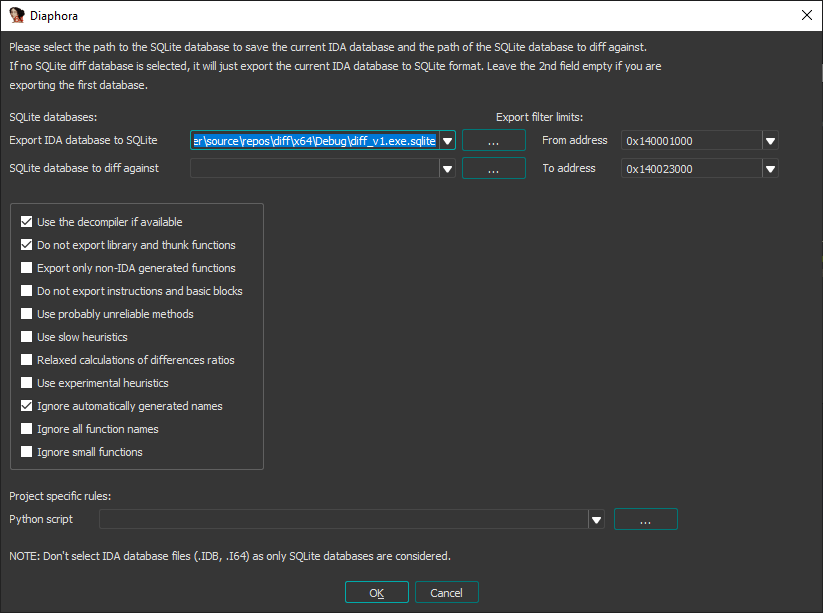
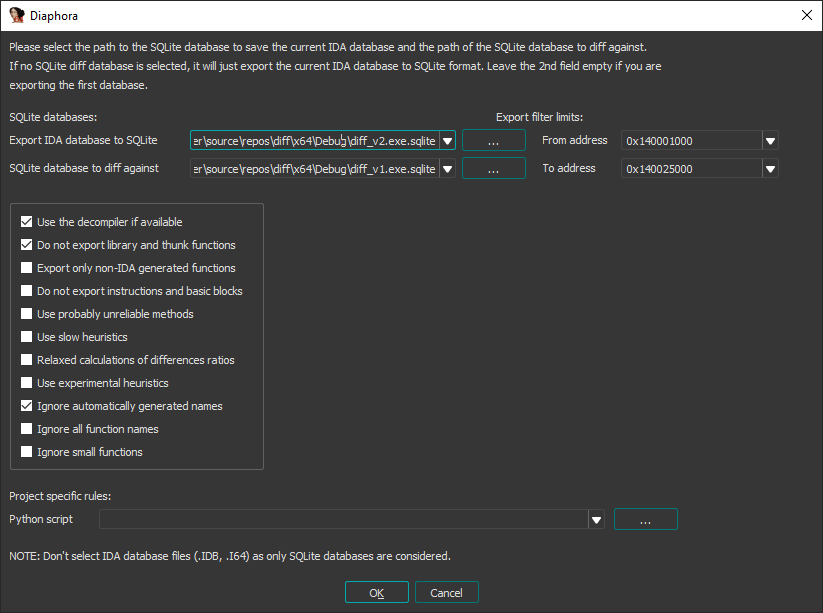
Diaphora is a plugin to IDA and it exports all necessary metadata into a sqlite-database. It then gives you a bunch of options as you can see below.
We first open a file in IDA and export all the necessary metadata into a sqlite-database before then opening the second file and comparing the sqlite files:
The UI after the comparison finishes is pretty much the same as BinDiff:

However when comparing functions side-by-side it’s all done in IDA with the option to get an assembly, a pseudo-code and a patch-style comparison.
Below is the patch comparison:
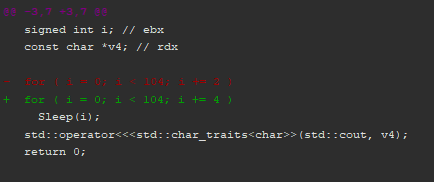
And next is the diff as shown in the pseudo-code:

In summary, they are both potent tools and in the context of diffing Windows patches it won’t really matter which you choose. As we have seen, the technique of binary diffing is useful for visualizing the difference between two binaries and is useful for purposes including variant analysis, vulnerability research and patch validation.
In the final part of this blog series, we will step through the process of diffing a Windows patch using the BinDiff tool.
References
- https://www.usenix.org/system/files/conference/usenixsecurity14/sec14-paper-bao.pdf
- https://www.hex-rays.com
- https://www.zynamics.com/bindiff/manual/index.html#N20367
- https://github.com/joxeankoret/diaphora/blob/master/doc/diaphora_help.pdf
- https://www.sto.nato.int/publications/STO%20Meeting%20Proceedings/RTO-MP-IST-091/MP-IST-091-26.pdf