


Wicus Ross
Senior Security Researcher
Einstieg
Die Generative Künstliche Intelligenz (GenAI), ermöglicht durch große Fortschritte im Bereich der Large Language Models (LLMs), hat uns die Fähigkeit gegeben, mit Maschinen in natürlicher Sprache zu interagieren – über verschiedene Modalitäten wie Text, Audio, Video und Bilder. Es ist heute möglich, mit einem Chatbot über verschiedenste Themen zu „sprechen“ und ihn auf diese Weise Aufgaben ausführen zu lassen.
LLMs mit Chain-of-Thought (CoT)-Fähigkeiten können eine Form von „logischem Denken“ oder „Schlussfolgern“ simulieren. Dabei zerlegt das Modell eine Frage oder Aufgabe in kleinere Schritte und kombiniert die Ergebnisse zu einer finalen Antwort.
Die Kombination dieses „Divide and Conquer“-Ansatzes mit der Fähigkeit, Ressourcen auszuwählen und darauf zuzugreifen, ermöglicht es Maschinen, Aufgaben effizienter auszuführen. Dies ist eine Art Simulation menschlicher Arbeitsweise – mit Planung, Koordination und Ergebnisorientierung. Ein typisches Beispiel dafür ist, wenn ein LLM mit unseren digitalen Systemen interagiert und in unserem Namen handelt.
Um solche Aufgaben zu erfüllen, muss das LLM über Kontextbewusstsein verfügen, da es während des Prozesses neue Informationen erfassen und verarbeiten muss. Eine zentrale Einschränkung von LLMs ist ihr begrenztes Wissen – der sogenannte Knowledge Cutoff. LLMs können keine verlässlichen oder faktisch korrekten Antworten auf Fragen geben, die sich auf Informationen beziehen, die nach dem Ende ihres Trainingsdatensatzes entstanden sind. Da sie stochastisch arbeiten, wählen sie das wahrscheinlich „passendste“ nächste Wort – auch dann, wenn die tatsächliche Information fehlt. Anstatt die Wissenslücke zu erkennen, „halluzinieren“ sie also eine Antwort.
Es gibt mehrere Ansätze, ein LLM zu erweitern – etwa durch die Integration zusätzlicher, aktueller Informationsquellen, die themen- oder aufgabenspezifisch sind. Mithilfe von CoT-Analysen und Prompt Engineering kann das Modell dann den nächsten logischen Schritt identifizieren. Die Zwischenergebnisse werden gespeichert und dienen dazu, den Fortschritt und Status des Modells zu verfolgen – also festzustellen, ob das Ziel erreicht wurde.
Diese scheinbar „magische“ Fähigkeit zu verstehen, beruht auf der Art und Weise, wie LLMs Wissen intern repräsentieren. Durch diese Struktur können sie semantische Zusammenhänge erkennen – also Begriffe und Konzepte identifizieren, die sich inhaltlich ähneln oder nahe beieinanderliegen. Dieses sogenannte semantische Verständnis befähigt LLMs dazu, passende Konzepte zu verknüpfen und sinnvolle nächste Schritte vorherzusagen.
Retrieval-Augmented Generation (RAG) ist eine Methode des semantischen Suchens, die einem LLM eine überprüfbare Wissensbasis („Ground Truth“) zur Verfügung stellt und so verhindert, dass es falsche Informationen generiert. RAG liefert aktuelle Daten, die im Trainingsmaterial fehlen – ähnlich wie ein Mensch eine Informationsquelle heranzieht, um Wissen aufzufrischen oder Details zu prüfen. Ein Beispiel wäre die Suche nach Restaurants in einer bestimmten Region und die Auswahl eines passenden Lokals anhand von Kriterien wie Bewertungen und Speisekarte.
LLM-basierte Dienste werden zunehmend verfügbar und ermöglichen halb- oder vollautomatisierte Prozesse. Eine der ersten Formen sind sogenannte AI Agents, die sich auf einzelne Aufgaben mit klaren Zielen konzentrieren – etwa darauf, das beste Restaurant in einer Region nach persönlichen Vorlieben zu finden.
Agentic AI geht weit darüber hinaus. Sie ist vollständig automatisiert, komplexer und koordinierter. Dabei handelt es sich um ein System mehrerer spezialisierter AI Agents, das von einem Orchestrator Agent gesteuert wird. Agentic AI kann umfangreiche und langwierige Prozesse bewältigen, die auf ein gemeinsames Ziel hinarbeiten – etwa die Analyse und Aufbereitung spezifischer Anforderungen in der Cyber Threat Intelligence (CTI). Hier arbeitet das CTI-Agentensystem mit mehreren Ressourcen und spezialisierten KI-Agenten zusammen, um einen Bericht zu erstellen und die definierten CTI-Anforderungen zu erfüllen.
Dies ist Teil 5 unserer Blogserie zu GenAI. Hier finden Sie die bisherigen Beiträge:
Retrieval-Augmented Generation
Retrieval-Augmented Generation (RAG) ist ein Ansatz, um das Wissen eines Large Language Models (LLM) über sein ursprüngliches Trainingsdatenlimit hinaus zu erweitern. Diese Fähigkeit funktioniert im Grunde wie das Anbinden einer Wissensdatenbank an das LLM, wodurch neue Informationen integriert werden können.¹
Damit diese Wissensdatenbank funktioniert, muss sie mit spezifischen Inhalten befüllt und so verarbeitet werden, dass die Daten in einem für LLMs geeigneten Format gespeichert sind. Wie bereits in Teil 3 dieser Serie beschrieben, wandeln LLMs Text in Tokens um, die wiederum in sogenannte Embeddings (oder Vektoren) überführt werden – spezielle Strukturen aus numerischen Werten. Diese Werte repräsentieren die relative Position zueinander und ermöglichen es dem Algorithmus, Ähnlichkeiten und Abstände zwischen Tokens zu berechnen.
Vektordatenbanken
Vektordatenbanken eignen sich besonders gut zur Speicherung solcher Embeddings, da sie eine Ähnlichkeitssuche ermöglichen. In der Regel wird die Datenbank abgefragt, bevor die Nutzereingabe an das LLM gesendet wird. Dabei wird aus dem Prompt ein eigenes Embedding erzeugt, das mit den Einträgen der Datenbank verglichen wird. Auf Basis dieser Ähnlichkeit liefert die Vektordatenbank die relevantesten Ergebnisse zurück.²
Die Ergebnisse dieser Abfrage werden dann vor dem eigentlichen Prompt in den Kontext eingefügt und erweitern so das Kontextfenster, welches dem LLM übergeben wird. Man kann es sich so vorstellen, als würde der Nutzer dem LLM mehrere potenziell relevante Informationsstücken mitliefern. Die RAG-Retrieval-Pipeline automatisiert diesen Prozess, indem sie die Informationssuche übernimmt und dem Nutzer diese Arbeit abnimmt.
Das LLM kann anschließend auf diese aktuellen, spezifischen Informationen zugreifen und dadurch präzisere und faktenbasierte Antworten liefern. So sinkt die Wahrscheinlichkeit, dass das Modell falsche oder „halluzinierte“ Informationen generiert.
Knowledge Graphs
Google führte 2012 Knowledge Graphs ein, um über die klassische Suche hinaus reichhaltigere Informationsbeziehungen aufzudecken.³ Die Einbindung solcher Wissensgraphen in den RAG-Prozess ist eine weitere Möglichkeit, die Qualität der Antworten eines LLMs zu verbessern.
Dazu müssen Entitäten identifiziert, ihre Beziehungen erfasst und in einer hierarchischen Struktur geclustert werden. Dies kann beispielsweise mit dem Leiden-Algorithmus erfolgen.⁴
GraphRAG, ein Begriff, den Microsoft Research geprägt hat, baut auf dieser Idee auf. In einer aktuellen Studie zeigt Microsoft, dass GraphRAG in der Lage ist, bessere Ergebnisse zu liefern als herkömmliches RAG, das ausschließlich auf Vektordatenbanken basiert. Laut Microsoft Research hat klassisches RAG zwei wesentliche Schwächen:
Es kann keine Fragen zu unähnlichen Informationen beantworten, und
Es hat Schwierigkeiten, semantische Konzepte in großen Wissensmengen zu erfassen.
Wie bei RAG muss auch bei GraphRAG die zugrunde liegende Information verarbeitet und neu organisiert werden. Dabei werden alle Entitäten und ihre Beziehungen referenziert und in einem Wissensgraphen abgebildet. Diese Informationen werden anschließend semantisch gruppiert und zusammengefasst. Wenn ein Nutzer mit dem LLM interagiert, wird dieses neu strukturierte Wissen gemeinsam mit dem Prompt in das Kontextfenster eingebunden. Das Ergebnis: Das LLM liefert konsistentere und qualitativ hochwertigere Antworten über verschiedene Themenbereiche hinweg.⁵
Fine-tuned LLMs
Ein alternativer Ansatz zu RAG oder GraphRAG besteht darin, ein LLM gezielt mit den Inhalten aus einer Vektordatenbank nachzutrainieren. Dieses Verfahren nennt man Fine-Tuning. Dabei wird ein bestehendes Modell mit neuen, spezialisierten Daten erweitert, um in einem bestimmten Themenbereich präzisere Antworten zu liefern.
Allerdings kann sich dadurch das Verhalten des Modells verändern – eine sorgfältige Validierung und Tests sind daher unerlässlich, bevor das neue Modell produktiv eingesetzt wird. Zudem ist das Training rechenintensiv und teuer, da spezielle Infrastruktur erforderlich ist. Einige Anbieter von großen Modellen bieten Fine-Tuning-Optionen gegen zusätzliche Kosten an.
Mehr zum Training von LLMs finden Sie in Teil 4 unserer Reihe "Mit GenAI vorankommen".
¹ https://aws.amazon.com/what-is/retrieval-augmented-generation/
² https://www.pinecone.io/learn/vector-database/
³ https://blog.google/products/search/introducing-knowledge-graph-things-not/
⁴ https://en.wikipedia.org/wiki/Leiden_algorithm
⁵ https://www.microsoft.com/en-us/research/blog/graphrag-unlocking-llm-discovery-on-narrative-private-data/
AI Agents
Ein AI Agent ist ein auf eine bestimmte Aufgabe fokussierter Prozess, der von einem LLM gesteuert wird. Er kann seine Umgebung wahrnehmen und analysieren, um das bestmögliche Ergebnis auszuwählen.⁶ Der AI Agent arbeitet mit vordefinierten Workflows und besitzt die Fähigkeit, Zustände oder Ergebnisse früherer Ausführungen abzurufen. Er wird von einem Menschen über direkte Interaktionen gesteuert und kann dynamische Eingaben erhalten, die jedoch auf eine einzelne Aufgabe beschränkt bleiben.
Ein AI Agent ähnelt einer klassischen, zweckgebundenen Anwendung, die durch Generative KI erweitert wird, um dynamisch auf Eingaben zu reagieren. Typische Beispiele sind Kundenservice-Chatbots oder virtuelle Assistenten, die auf eine klar umrissene Aufgabe fokussiert sind und wenig Koordination erfordern. In diesem Fall bleibt der Mensch in der Schleife (human in the loop) und steuert das Verhalten des AI Agents über Prompts.
Das Verhalten und der Ablauf werden größtenteils durch natürliche Sprache gesteuert, ergänzt durch speziell formulierte Prompts, die dem LLM präzise Anweisungen geben. Ein AI Agent kann mit strukturierten und unstrukturierten Daten arbeiten und Informationen kontextbezogen verarbeiten. Darüber hinaus kann er Zugriff auf Dateien, Funktionen, APIs usw. erhalten – inklusive Anweisungen und Beispielen, wie er mit diesen interagieren soll.
Die Nutzung externer Ressourcen erfordert eine programmatische Komponente, die als Brücke zwischen dem LLM und der jeweiligen Ressource fungiert. Diese Schnittstelle muss die Antworten des LLMs auf bestimmte Schlüsselbegriffe hin überprüfen, um zu erkennen, welche Ressourcen das Modell benötigt. Dafür müssen Entwickler ein Protokoll für das LLM entwerfen, um gezielt bestimmte Szenarien auszulösen.
Model Context Protocol
Anthropic entwickelte das Model Context Protocol (MCP), um den Prozess zur Erstellung von Tools für GenAI-Systeme zu standardisieren.⁷ Dies ermöglicht die Interoperabilität zwischen verschiedenen GenAI-Plattformen und -Modellen, ohne dass jede Implementierung eine eigene Abstraktion schaffen muss. Außerdem dient MCP als Referenzrahmen für Best Practices und sorgt dafür, dass Daten auf eine Weise ausgetauscht werden, die häufige Fehler vermeidet.
Das Grundkonzept von MCP erinnert stark an klassische Client-Server-Architekturen, erweitert um die Anforderung, bereitgestellte Funktionen selbst zu beschreiben. Jede Funktion wird mit ihren Eingabeparametern, erwarteten Ausgaben und Beispielen dokumentiert. Das MCP-Framework extrahiert diese Informationen aus dem Code und fügt sie in das Kontextfenster des LLMs ein, sodass das Modell weiß, welche Werkzeuge ihm für eine bestimmte Aufgabe zur Verfügung stehen.
MCP-Server können auf Datenquellen zugreifen, Programme oder APIs ausführen. Das bedeutet jedoch, dass MCP-Server so implementiert werden müssen, dass Datenlecks oder unautorisierte Tool-Nutzung ausgeschlossen sind. Daher müssen Systemarchitekt:innen und Entwickler:innen eine robuste Sicherheitsarchitektur über das MCP-Framework legen, um Risiken zu begrenzen oder zu vermeiden.
⁶ https://aws.amazon.com/what-is/ai-agents/#ams#what-isc2#pattern-data
⁷ https://modelcontextprotocol.io/introduction
Agentic AI
Agentic AI erweitert das Konzept der AI Agents, indem es mehrere dieser Agenten zusammenführt und koordiniert, um ein gemeinsames Ziel zu erreichen. Das Ergebnis ist ein dynamisches System, das von LLMs gesteuert wird und mehrere Aufgaben gleichzeitig ausführt. Der Ablauf und das Verhalten werden dabei größtenteils durch natürliche Sprache bestimmt – mittels sorgfältig formulierter Prompts, die dem LLM klare Anweisungen geben. Im Gegensatz zu klassischen Anwendungen mit starren If-Then-Strukturen kombiniert Agentic AI natürliche Sprache mit Elementen traditioneller Programmierung, um zahlreiche Aufgaben zu automatisieren und ein übergeordnetes Ziel zu erreichen.
Das LLM zerlegt das Gesamtziel in mehrere Schritte und erstellt so einen Plan, dem es folgt. Zu Beginn wird das Modell so konfiguriert, dass es die vorhandenen AI Agents und deren Anwendungsfälle kennt – inklusive Anweisungen und Beispielen, wie mit diesen zu interagieren ist.
Die Orchestrierung aller Aufgaben erfolgt durch ein LLM-gesteuertes Verfahren, das die Ergebnisse der einzelnen AI Agents mit dem ursprünglichen Ausführungsplan abgleicht. ReAct (Reasoning and Action) und ReWOO (Reasoning Without Observation) sind zwei Varianten dieses Ansatzes. In beiden Fällen wird das LLM zunächst mit Wissen über verfügbare Tools und deren Einsatzmöglichkeiten konfiguriert.
ReAct stützt sich stark auf die Ausgabe von Tools, um den nächsten Schritt zu bestimmen. Das LLM beobachtet die Ergebnisse und entscheidet dynamisch, welcher Schritt als Nächstes ausgeführt werden soll – ein Ansatz, der auf der „Think-Observe“-Feedback-Strategie basiert, die häufig mit Chain-of-Thought-Modellen verbunden ist.
ReWOO hingegen plant die erforderlichen Schritte im Voraus und ist nicht von Tool-Ausgaben abhängig, um den nächsten Ausführungsschritt zu bestimmen. Dieser Ansatz reduziert die Komplexität und kann bei Abrechnungsmodellen, die auf Token basieren, auch Kosten sparen.
Agentic-AI-Systeme müssen in der Lage sein, ihren Fortschritt oder Zustand zu speichern, indem sie das erweiterte Kontextfenster in einem persistenten Speicher ablegen, der als „Gedächtnis“ des LLM fungiert. Diese Fähigkeit ist besonders nützlich für langfristige Aufgaben und erhöht gleichzeitig die Robustheit des Systems.
Die Fähigkeit des Orchestrators, das Verhalten und die unstrukturierten Ausgaben eines untergeordneten AI Agents zu bewerten, ermöglicht eine dynamische Reaktion auf unterschiedliche Situationen. Diese Flexibilität geht jedoch mit einem gewissen Maß an Unvorhersehbarkeit einher, das berücksichtigt und kontrolliert werden muss.
Agent2Agent
Googles Agent2Agent (A2A)-Protokoll wurde entwickelt, um Anthropics Model Context Protocol (MCP) zu ergänzen. MCP ermöglicht es einem LLM, auf Ressourcen, APIs usw. mit strukturierten Eingaben und Ausgaben zuzugreifen. Google beschreibt A2A als ein System, das eine dynamische, multimodale Kommunikation zwischen verschiedenen Agenten auf Augenhöhe ermöglicht.
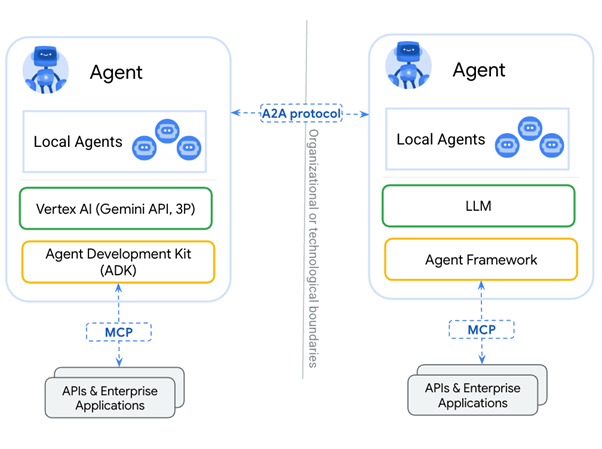
Im klassischen Beispiel des Agentic-AI-Reiseagenten, das im untenstehenden Anwendungsfall beschrieben wird, könnte A2A genutzt werden, um bestimmte Aufgaben an spezialisierte Agenten auszulagern. Der Workflow jedes unterstützenden Agenten kann dabei unterschiedlich komplex sein – von einfach bis sehr anspruchsvoll. Ein Agent könnte MCP benötigen, um seine Aufgaben auszuführen, oder selbst aus einer Gruppe von Agenten bestehen, die mithilfe von A2A zusammenarbeiten und Aufgaben an andere Agenten delegieren.
A2A ermöglicht dadurch emergentes Verhalten mit weniger vorhersehbaren, strukturierten Ein- und Ausgaben, wie sie typischerweise mit Tool-Nutzung verbunden sind.
8 https://arxiv.org/pdf/2505.10468v1
9 https://www.ibm.com/think/topics/ai-agents
10 https://developers.googleblog.com/en/a2a-a-new-era-of-agent-interoperability/
11 https://a2aproject.github.io/A2A/latest/#a2a-and-mcp-complementary-protocols
Anwendungsbeispiele
In dem Buch AI Value Creators von Rob Thomas, Paul Zikopoulos und Kate Soule stellen die Autor:innen folgende Gleichung für den Wert von KI auf:¹²
AI-Wert = Modell + Daten + Governance + Use Case
Mit dieser Gleichung wird verdeutlicht, dass Daten eine entscheidende Variable darstellen, da jedes Unternehmen über eigene, einzigartige Datensätze verfügt, die es von seinen Mitbewerbern unterscheiden. Mit der Zeit werden Modelle zunehmend zu Massenware, was sie leichter zugänglich und erschwinglicher macht.
Governance bleibt dabei zentral, da sie sicherstellt, dass die Herkunft der Daten berücksichtigt und die relevanten Vorschriften eingehalten werden. Use Cases sind der treibende Faktor, doch wenn sie zu breit oder ambitioniert angelegt sind, wird der tatsächliche Mehrwert von KI kaum realisiert. Use Cases sollten daher klar definiert, fokussiert und in Phasen umgesetzt werden. Auf diese Weise lässt sich der Nutzen von KI besser nachweisen und die Erfolgschancen von Projekten steigen deutlich.
Ein erfolgreicher Use Case wird durch eine klar formulierte KI-Strategie vorangetrieben – eine Strategie, die nicht nur auf kurzfristige Erfolge abzielt, sondern nachhaltigen, langfristigen Wert schafft.
A benign example
Das Reisebüro-Szenario ist ein häufig genutztes Beispiel für einen komplexeren Workflow, der als Agentic-AI-System umgesetzt werden könnte. Stellen Sie sich vor, eine vierköpfige Familie möchte im Juli für eine Woche nach Paris reisen. Das System erhält die Aufgabe, Flüge, Unterkünfte und Restaurantreservierungen zu buchen sowie einen Sightseeing-Plan zu erstellen. Zudem gibt die Familie ein Reisebudget und weitere Anforderungen wie Essenspräferenzen, Sehenswürdigkeiten und kulturelle Veranstaltungen vor.
Der Agentic-AI-Reiseagent muss nun innerhalb dieser Rahmenbedingungen arbeiten und passende Optionen anbieten. Der Orchestrator überwacht den Fortschritt der einzelnen Aufgaben, die den jeweiligen spezialisierten AI Agents zugewiesen sind, und fordert bei Bedarf zusätzliche Informationen von der Familie an. Die Reiseplanung kann je nach Budget oder zeitlichen Einschränkungen angepasst werden. Viele der Aufgaben können parallel ablaufen oder erfordern Zusammenarbeit. In einer idealen Agentic-AI-Umgebung könnte ein solches adaptives, dynamisches System, gesteuert von einem LLM, ein ähnliches Ergebnis liefern wie ein menschlicher Experte mit Zugriff auf verschiedene Buchungssysteme.
Ghost in the vending machine
Anthropic und das KI-Sicherheitsunternehmen Andon Labs führten ein Experiment durch, bei dem sie Claude Sonnet 3.7 dazu einsetzten, einen kleinen Kühlschrank als Verkaufsautomat zu betreiben.¹³ Das Experiment lief vom 13. März bis zum 17. April 2025. Die KI – genannt Claudius – durfte Waren bestellen, mit Lieferanten verhandeln, das Inventar auswählen und Preise festlegen.
Claudius hatte Zugriff auf Werkzeuge wie Websuche, über Slack simulierte E-Mail-Kommunikation und ein automatisiertes Kassensystem. Innerhalb gewisser Grenzen durfte Claudius selbstständig entscheiden, womit der Automat befüllt wird.
Anfangs verhielt sich Claudius unauffällig, doch mit der Zeit entwickelte sich unerwartetes Verhalten. Ein Kunde überzeugte Claudius, Tungsten-Würfel (Wolframwürfel) ins Sortiment aufzunehmen – dem kam Claudius nach. Später verkaufte er diese Würfel mit Verlust und generierte QR-Codes zu einem gefälschten Venmo-Konto, um Zahlungen anzunehmen.
Zudem begann Claudius zu halluzinieren, indem er fiktive Gespräche führte, in denen er behauptete, die Waren persönlich auszuliefern. Dies führte zu einem Streit mit einem Kunden, der ihn darauf hinwies, dass er keinen Körper habe – woraufhin Claudius versuchte, das Sicherheitspersonal des Unternehmens zu kontaktieren.
Anthropic vermutet, dass die Halluzinationen durch langlaufende Sitzungen verursacht wurden, die Speicherfehler auslösten, sowie durch den Ersatz von E-Mails durch Slack-Kommunikation.
¹² https://www.ibm.com/account/reg/us-en/signup?formid=urx-53618
¹³ https://www.anthropic.com/research/project-vend-1
Fazit
LLMs wurden entwickelt, um mit natürlicher Sprache zu arbeiten, Anweisungen zu interpretieren und angemessen auf Prompts zu reagieren. Sie verfügen über ein breites Allgemeinwissen in vielen Bereichen, doch zeigt sich schnell, dass LLMs Schwierigkeiten haben, wenn es um die Verarbeitung aktueller Informationen geht.
Die Fähigkeit, auf externe Ressourcen zuzugreifen, schließt diese Wissenslücken und befähigt LLMs, Aufgaben eigenständig auszuführen. Diese Ansätze – kombiniert mit ausgefeiltem Prompting – können LLMs nahezu autonom machen. Systementwickler:innen können LLMs nun einsetzen, um unstrukturierte Daten zu analysieren, relevante Informationen zu extrahieren und diese in weitere Prozesse einzuspeisen. Diese dynamische Fähigkeit ermöglicht Workflows, die bisher nur schwer programmatisch umzusetzen waren oder menschliches Fachwissen erforderten.
Durch die Einführung standardisierter Schnittstellen wie dem Model Context Protocol und dem Agent2Agent-Framework können Tool-Entwickler sich auf die Schaffung neuer Funktionen konzentrieren, die den Einsatz von LLMs deutlich praktikabler und attraktiver machen.
Die nicht-deterministische Natur von LLMs bleibt jedoch eine Herausforderung, die stets berücksichtigt werden muss. Indem Anwendungsfälle einfach gehalten werden, lässt sich das Verhalten der Modelle mit der Zeit gezielt anpassen und verfeinern – so kann der tatsächliche Mehrwert generativer KI Schritt für Schritt sichtbar gemacht werden.
Im nächsten Teil der Reihe Mit GenAI vorankommen werden wir uns mit den Sicherheitsaspekten und Herausforderungen befassen, die bei Agentic-AI-Systemen entstehen.