

1 von 4 – Mit GenAI vorankommen
22 Juli 2025


Wicus Ross
Senior Security Researcher
Willkommen zum letzten Teil unserer Blogreihe über Generative KI (GenAI). In diesem Beitrag setzen wir die Betrachtung der Schritte zum Aufbau eines Large Language Models (LLM) fort. Im vorherigen Blogpost haben wir uns mit den Pretraining-Schritten beschäftigt. Dabei ging es um die Datensammlung und -aufbereitung, die Tokenisierung und Embeddings sowie einen ersten Einblick in neuronale Netzwerke.
Darauf aufbauend schließen wir nun diesen Abschnitt ab, indem wir uns mit dem Ergebnis des Pretrainings, dem sogenannten Basismodell, und den anschließenden Aktivitäten im Posttraining befassen.
Bitte beachten Sie, dass diese Blogreihe einen Überblick auf hoher Ebene bietet und nicht als Schritt-für-Schritt-Anleitung gedacht ist. Vielmehr sollen die Beiträge Ihnen einen Einstieg in das Thema ermöglichen und als Ausgangspunkt für weiterführende Recherchen dienen. Nutzen Sie dafür auch die bereitgestellten Quellen, die Sie bei tiefergehenden Fragen unterstützen und Ihnen als Nachschlagewerk dienen können.
Falls Sie die bisherigen Beiträge noch nicht gelesen haben oder Ihr Wissen auffrischen möchten, finden Sie weitere Informationen in Teil 1, Teil 2 und Teil 3 dieser Serie. Teil 3 behandelt den Pretraining-Schritt, der eine zentrale Rolle bei der Entwicklung eines LLMs spielt und direkt auf diesen Blogpost vorbereitet.
Ein Basismodell ist das Ergebnis des abgeschlossenen Pretraining-Schritts, den wir in Teil 3 dieser Blogreihe behandelt haben. Man kann sich ein Basismodell als eine Art Textsimulator vorstellen, der das Trainingsmaterial „gelernt“ hat und nun in der Lage ist, auf Grundlage dieser Daten Vorhersagen über das nächste Wort in einer Textsequenz zu treffen.
Die Größe eines Modells ergibt sich aus einer Kombination der Architektur und dem Ausbau der Struktur des neuronalen Netzwerks. In der Regel wird sie in der Anzahl der Parameter gemessen. Moderne LLMs verfügen oft über Milliarden solcher Parameter, auch Gewichte genannt, wobei beide Begriffe häufig synonym verwendet werden.
Ein Basismodell wird durch eine Sammlung von Dateien dargestellt. Diese umfassen die Konfiguration der Netzwerkarchitektur, die festgelegten Hyperparameter, Metadaten, die Tokenisierung- und Vokabularzuordnungen sowie die Modellgewichte. ¹ Diese Gewichte können sehr umfangreich sein und sind daher meist auf mehrere Dateien aufgeteilt, die jeweils mehrere Gigabyte groß sein können. Zum Beispiel hat Metas LLaMA 4 Scout 17B 16E mit 17 Milliarden Parametern eine Gesamtdatengröße von rund 216 Gigabyte. ²
Eines der ersten öffentlich zugänglichen Transformer-Basismodelle mit offenen Gewichten war GPT-2 von OpenAI.³ Im Vergleich zu heutigen Modellen war es noch recht rudimentär. Um eine bestimmte Art von Ausgabe zu erhalten, musste man dem Modell ein Beispiel mitliefern. GPT-2 versuchte dann, diesem Muster zu folgen. Eine einfache Variante bestand darin, dem Modell einen Textanfang zu geben, woraufhin es ein oder zwei Absätze fortsetzte. Dabei wurde deutlich, dass das Modell im Kern versucht, das nächste Token oder Wort möglichst treffend vorherzusagen. ⁴
Im Jahr 2019 war das ein bedeutender Fortschritt und für die Forschung äußerst spannend, aber der praktische Nutzen war noch begrenzt. Heute können Basismodelle innerhalb von Sekunden Hunderte von Wörtern erzeugen und auf deutlich komplexere Eingaben reagieren. Seitdem wurden zahlreiche Verfahren zur Leistungsbewertung und Modellvergleiche entwickelt, mit denen sich besser einschätzen lässt, wie gut ein Modell in bestimmten Anwendungsszenarien funktioniert.
In der Regel veröffentlichen die Entwickler eines Modells eine sogenannte Model Card sowie optional ein Paper, in dem das LLM, seine wichtigsten Eigenschaften und geplanten Anwendungsbereiche beschrieben werden.⁵ Dazu gehört häufig auch ein Überblick über die Pretraining-Phase, in der die wesentlichen Komponenten des Modells definiert werden.
Zusätzlich wird das Modell anhand einer Reihe standardisierter Benchmarks bewertet, die bestimmte Fähigkeiten prüfen, wie etwa Sprachverständnis, Mathematik, logisches Denken, Programmieren oder die Fähigkeit, Anweisungen präzise zu befolgen. Dabei werden unterschiedliche Metriken erfasst, aus denen dann ein Gesamtergebnis abgeleitet wird, das einen Vergleich mit anderen Modellen ermöglicht.⁶
Typische Bewertungsmetriken sind unter anderem:
Wie bei jeder Metrik sind auch diese Kennzahlen nicht perfekt und können durch gezieltes Training auf genau diese Tests manipuliert werden. Das kann zu Overfitting führen, bei dem das Modell Antworten regelrecht „auswendig lernt“. Dadurch sind zwar die Benchmark-Ergebnisse hervorragend, doch im realen Einsatz können die tatsächlichen Leistungen deutlich schwächer ausfallen.
Deshalb müssen Benchmarks mit dem Fortschritt der LLMs Schritt halten, um deren Grenzen weiterhin sinnvoll zu testen. Dazu gehört auch, dass die Tests vielfältiger werden und gezielt Fachwissen und komplexe Aufgabenstellungen abfragen.
Beispiele für etablierte Benchmarks (Auswahl):
SimpleBench ist ein neuer Benchmark und basiert auf Multiple-Choice-Fragen. Er ordnet LLMs im Vergleich zum menschlichen Leistungsniveau ein. Zum besseren Verständnis: Der menschliche Referenzwert liegt bei 83,7 %. Anfang April 2025 erreichte das beste reasoning-basierte Modell nur 51,6 %.
Ranglisten wie jene von lmarena.ai sind unterhaltsam und aufschlussreich, sollten jedoch mit Vorsicht interpretiert werden, da manche dieser Bewertungen auch auf Community-Stimmung beruhen.¹⁶ Eine vielseitigere Plattform wie livebench.ai ermöglicht es, Modelle auf Basis unterschiedlicher Benchmarks zu vergleichen.¹⁷
Oft zeigen diese Ranglisten nicht nur Basismodelle, sondern auch stark feinjustierte (finetuned) Varianten. Diese spezialisierten Modelle schneiden in der Regel in Benchmarks besser ab als ihre ursprünglichen Basismodelle. Daher sollte man beim Bewerten eines Modells stets mehrere Benchmarks und unabhängige Bewertungen heranziehen.
5 https://arxiv.org/pdf/1810.03993
6 https://www.ibm.com/think/topics/llm-benchmarks
7 https://rowanzellers.com/hellaswag/
8 https://arxiv.org/abs/1905.07830
9 https://leaderboard.allenai.org/arc/submissions/public
10 https://arxiv.org/abs/2109.07958
11 https://arxiv.org/abs/2110.14168
12 https://arxiv.org/abs/2107.03374
13 https://simple-bench.com/
14 https://arxiv.org/abs/2311.12022
15 https://openai.com/index/mle-bench/
16 https://lmarena.ai/?leaderboard
17 https://livebench.ai/
Wir haben bereits früher auf den Inferenzprozess hingewiesen, als wir über die Prompt Completion gesprochen haben. Inferenz (Inference) bedeutet im Grunde, dass das Modell „ausgeführt“ wird, indem man ihm eine Eingabe (Prompt) zur Vervollständigung übergibt.¹⁸
Der Inferenzprozess, die Berechnung zur Nutzungszeit (test-time compute), unterscheidet sich deutlich vom Trainingsprozess (train-time compute). Ein großer Teil der Optimierungsarbeit bei LLMs konzentriert sich auf die Inferenzphase, denn genau hier verbringen Nutzer die meiste Zeit: beim Warten darauf, dass das Modell den nächsten Token generiert.¹⁹
Je schneller der Inferenzprozess abläuft, desto geringer ist die Latenz bei der Generierung von Antworten, was zu einer besseren Nutzererfahrung führt.
Quantisierung ist ein Verfahren zur Reduzierung des Speicherbedarfs eines Modells – sowohl in Bezug auf den benötigten Arbeitsspeicher zur Laufzeit als auch auf den Speicherplatz zur Ablage. Dabei ist die Reduktion des Laufzeitspeichers besonders wichtig, da dieser meist sehr begrenzt und teuer ist.
Der Parametertyp eines Modells beeinflusst maßgeblich, wie viel Arbeitsspeicher und Speicherplatz es benötigt und auch, wie schnell und präzise es arbeitet. Ein LLM lässt sich vereinfacht als eine große Datenstruktur beschreiben, in der jeder Eintrag ein Zahlenwert ist. In der Regel handelt es sich dabei um Fließkommazahlen (engl. floating point) zwischen 0 und 1. Diese Werte können aber auch als Ganzzahlen (integers) dargestellt werden.
Technisch gesehen stehen derzeit folgende Varianten für das Training vortrainierter Modelle zur Verfügung:²⁰
BF16 ist heute besonders verbreitet, da es einen guten Kompromiss zwischen Speicherverbrauch, Geschwindigkeit und Genauigkeit bietet.
Weitere Effizienzgewinne sind beim Finetuning eines Modells durch folgende Methoden möglich:
4NF und INT8 ermöglichen es, Modelle auf kostengünstiger Hardware oder sogar auf verbrauchertauglichen Geräten laufen zu lassen, allerdings auf Kosten der Modellgenauigkeit.
Ein Basismodell muss zunächst feinjustiert (finetuned) werden, um es für einen bestimmten Anwendungsfall nutzbar zu machen etwa als „Chat“-Assistent. Dazu werden Verfahren eingesetzt, die dem Modell anhand zahlreicher Beispiele beibringen, wie es sich bei bestimmten Eingaben (Prompts) verhalten soll. Mit Hilfe einer großen Menge an Beispielen von Anfrage-Antwort-Paaren kann dem Modell gezielt ein gewünschtes Verhalten antrainiert werden.
Zur Unterstützung dieses Prozesses kann auch synthetisches Testmaterial verwendet werden. Dieses wird von speziell trainierten neuronalen Netzwerken erzeugt, die die Antworten des LLM bewerten und eine Punktzahl vergeben, die zur weiteren Optimierung des Modells herangezogen wird. Reinforcement Learning ist eine dieser Techniken, mit der sich das Training in großem Maßstab durchführen lässt, ohne dass Menschen jede einzelne Antwort bewerten müssen.
Darüber hinaus lassen sich Modelle auch so trainieren, dass sie ihre eigenen Grenzen erkennen und keine erfundenen Inhalte erzeugen, nur um den Nutzer zufriedenzustellen.
Supervised Finetuning (SFT) kann man sich als eine Methode vorstellen, mit der ein LLM gezielt auf ein bestimmtes Verhalten ausgerichtet wird. Dabei wird das Basismodell mithilfe von Beispiel-Prompts und den dazu gewünschten Antworten angepasst. Dies stellt einen neuen Trainingsdurchlauf dar, bei dem zusätzliches Material verwendet wird, konkret die Gespräche zwischen Nutzer und KI-Assistent.
Diese Konversationen werden von menschlichen Expertinnen und Experten erstellt, die das Trainingsmaterial mit einer Vielzahl an Themen anreichern. ²⁴ Der Erfolg dieses Prozesses hängt stark davon ab, wie gut Menschen in der Lage sind, qualitativ hochwertige und zielführende Beispielkonversationen bereitzustellen.
Die meisten SFT-Datensätze sind proprietär und in der Herstellung sehr aufwendig, weshalb sie in der Regel nicht öffentlich geteilt werden. Es gibt jedoch einige offene Beispieldatensätze, die zur Feinabstimmung eines Basismodells genutzt werden können, sie eignen sich als Ausgangspunkt zur Erweiterung eigener Datenbestände.²⁵ ²⁶ Dabei ist jedoch Vorsicht geboten: Diese offenen Datensätze sollten sorgfältig geprüft werden, da ihre Inhalte unerwünschte Nebeneffekte im Modellverhalten hervorrufen können.
24 https://arxiv.org/pdf/2203.02155
25 https://huggingface.co/datasets/OpenAssistant/oasst1
26 https://github.com/thunlp/UltraChat
Eine Halluzination tritt auf, wenn ein LLM eine falsche Antwort auf eine Frage generiert, anstatt zuzugeben, dass es die Antwort nicht kennt. Die Gesprächsbeispiele, die im Rahmen des Post-Trainings verwendet werden, dienen dem Modell als Vorlagen, die es später während des Inferenzprozesses bei echten Nutzeranfragen nachahmt. Wenn genügend hochwertige Beispiele vorhanden sind, verbessert sich in der Regel auch die Qualität der Antworten. Da ein LLM jedoch die nächsten Token basierend auf Wahrscheinlichkeiten „errät“, besteht immer ein Risiko, dass es eine fiktive und potenziell falsche Antwort erzeugt.
Das Risiko solcher Halluzinationen lässt sich verringern, indem man dem Modell gezielt Antwortmuster vorgibt, in denen es nicht über ausreichendes Wissen verfügt. Diese Beispiele können sich auf Informationen beziehen, die nach dem Trainingszeitpunkt liegen, wie etwa aktuelle Nachrichten oder Ereignisse. In der SFT-Phase kann ein Prompt Engineer etwa eine Eingabe formulieren, auf die das Modell mit „Das weiß ich leider nicht“ reagieren soll. Dadurch wird das Modell darin „trainiert“, Nichtwissen zuzugeben, anstatt unzutreffende Fakten zu erfinden.
Ein skalierbarerer Ansatz besteht darin, Textausschnitte aus den Pretraining-Daten zu extrahieren und dem Modell dazu gezielt Fragen zu stellen. Die Antworten werden dann von einer speziell entwickelten Bewertungsplattform oder einem anderen LLM beurteilt, das auf Frage-Antwort-Paare trainiert wurde. Dieses Verfahren erzeugt eine Feedback-Schleife, die genutzt werden kann, um das Modell systematisch zu verbessern und die Halluzinationsneigung zu senken.²⁷ ²⁸
Ebenso kann ein Modell darauf trainiert werden, auffällige oder schädliche Prompts zu erkennen, z. B. solche mit gewalttätigem, rassistischem, hasserfülltem oder illegalem Inhalt. Hierzu werden entsprechende Beispiele mit einer gewünschten Antwort wie „Ich kann diese Anfrage leider nicht beantworten“ versehen. Dies betrifft den Aspekt der Alignment, also der gezielten inhaltlichen Ausrichtung des Modells durch das verantwortliche Entwicklerteam während der SFT- oder weiterer Feinabstimmungsphasen.
27 Grattafiori et al., The Llama 3 Herd of Models, 2024, pages 26-27 https://arxiv.org/pdf/2407.21783
28 https://arxiv.org/html/2407.17468v1
Reinforcement Learning ist ein Verfahren, mit dem ein LLM weiter trainiert wird, basierend auf einem Belohnungssystem, das das Modell dazu anregt, verschiedene Lösungswege zu erkunden, um ein bestimmtes Ergebnis zu erreichen.
Ein Modell erhält zunächst einen Prompt mit einer eindeutig überprüfbaren Antwort, zum Beispiel eine Mathefrage, auf die es nur eine richtige Lösung gibt. Das Modell soll nun nicht nur die Antwort liefern, sondern auch erklären, wie es zu diesem Ergebnis kommt. Ein weiteres System bewertet die verschiedenen Antwortvorschläge und vergibt eine Punktzahl.
Diese Rückmeldungen werden verwendet, um die Modellparameter anzupassen. Der Prozess wird wiederholt, bis das Modell schließlich in der Lage ist, gut strukturierte und kontextuell passende Ausgaben zu erzeugen.²⁹
Der Reinforcement-Prozess kann skalierbar gestaltet werden, indem man mit einer Vorlage beginnt, die genutzt wird, um eine große Menge an Trainingsdaten automatisch zu generieren. Das Belohnungssystem wirkt dabei wie ein Lenkmechanismus, der das Modell zu bestimmten gewünschten Eigenschaften oder Verhaltensweisen hinführt, auch bekannt als emergente Fähigkeiten.
Dies kann als eine Form des Finetunings eines LLM betrachtet werden und ähnelt auf den ersten Blick dem klassischen Reinforcement Learning. Die Methode Reinforcement Learning with Human Feedback (RLHF) wurde entwickelt, um die Leistung von Sprachmodellen in Bereichen zu verbessern, in denen Antworten oder Reaktionen auf Prompts nuanciert und stark von menschlichem Urteil oder Geschmack abhängig sind.³⁰
RLHF ist jedoch kostspielig, da das Erstellen eines hochwertigen Trainingsdatensatzes eine sorgfältige Bewertung durch Fachexperten erfordert.³¹
Wie beim klassischen Reinforcement Learning wird ein „Richter“ erstellt, der menschliches Urteil in einem bestimmten Fachbereich simuliert, zum Beispiel im kreativen Schreiben. Dieser Richter kann ein eigenes neuronales Netzwerk sein, das darauf trainiert wird, Texte auf Basis von Prompts so zu bewerten, wie es ein Mensch tun würde. Experten auf dem jeweiligen Gebiet geben dazu ihr Feedback, das wiederum genutzt wird, um den Bewertungsmechanismus, das „Judge Model“, zu trainieren.
Ist der Richter einmal trainiert, werden dem zu bewertenden LLM dieselben Prompts vorgelegt, die auch zur Schulung des Judge Models verwendet wurden. Das LLM generiert eine Antwort und der Richter vergibt dafür eine Punktzahl. Diese Bewertung wird genutzt, um die Parameter des LLM entsprechend anzupassen:
Laut Andrej Karpathy birgt RLHF sowohl Chancen als auch Herausforderungen.³²
Der Vorteil besteht darin, dass es einfacher ist, menschliche Expertinnen und Experten einzubeziehen, um die Trainingsdaten für das Judge Model zu erstellen. Karpathy nennt dies die Lücke zwischen Generator und Diskriminator: Es fällt Menschen oft leichter, etwas zu bewerten (diskriminieren), als es selbst zu erstellen (generieren).
Der Nachteil: Auch das Judge Model ist ein neuronales Netz und damit lediglich eine statistische Approximation menschlichen Verhaltens. Es kann passieren, dass das System Antworten als gut bewertet, die für Menschen sinnlos oder unpassend erscheinen.
Aus Erfahrung hat sich gezeigt, dass die Trainingsphase mit RLHF nicht zu lange dauern sollte. Wird dieser Schritt überdehnt, kann dies dazu führen, dass die Qualität der Modellantworten deutlich abnimmt, da das Modell möglicherweise überangepasst wird.
Ein „Thinking Model“ im Kontext von generativer künstlicher Intelligenz (GenAI) ist ein konzeptioneller Begriff, der sich auf bestimmte Prompting-Techniken bezieht, mit denen ein LLM eine komplexe Nutzeranfrage in einfachere Teilschritte zerlegt. Diese Zwischenschritte werden einzeln bewertet und zusammengefasst, ihre Kombination bildet dann die abschließende Antwort.
Es ist faszinierend, diesen Vorgang zu beobachten, da das Modell dabei wirkt, als würde es eine innere Stimme oder ein inneres Nachdenken zeigen.³³
Solche „Thinking Models“ werden in ähnlicher Weise trainiert wie Modelle, die mithilfe von Reinforcement Learning with Human Feedback (RLHF) optimiert wurden.³⁴ ³⁵
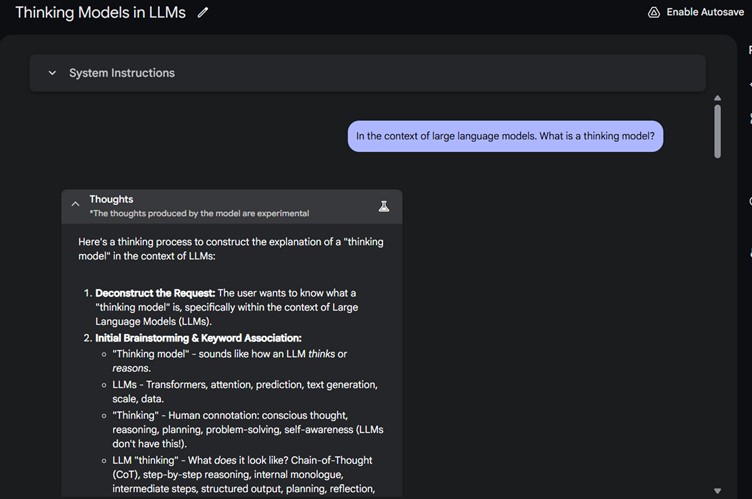
Der Chain-of-Thought (CoT)-Prozess, bei dem ein LLM einzelne Gedankenschritte zusammenstellt, vermittelt den Eindruck, dass das Modell seine Antwort plant und gleichzeitig Annahmen oder Hypothesen überprüft. In manchen Fällen erkennt das Modell sogar eigene Fehler und korrigiert sich selbst. Dieser Ansatz trägt zur Transparenz bei und ermöglicht es, die einzelnen Schritte durch Menschen auf Korrektheit zu überprüfen.
Es wird außerdem behauptet, dass dieser Ansatz das Risiko von Halluzinationen reduziert, da das LLM seine Antwort auf mehreren Wegen prüfen kann, bevor es zu einem Schluss kommt.
Thinking Models eignen sich besonders gut für komplexe, weit gefasste Fragestellungen, die mehrere Fakten oder Hypothesen berücksichtigen müssen. Sie benötigen jedoch mehr Zeit, um auf Prompts zu reagieren, da sie zusätzliche Informationen erzeugen, bevor sie die eigentliche Antwort liefern. Diese Reaktionszeit kann deutlich länger sein, teils mehrere Sekunden mehr als bei einem „nicht-denkenden“ Modell.
Das Unternehmen Anthropic bezeichnet Thinking Models als Simulated Reasoning (SR). In einer veröffentlichten Studie stellte Anthropic jedoch fest, dass SR-Modelle ihre „Denkprozesse“ oft nicht offenlegen.³⁶
Dabei ist es wichtig zu betonen: LLMs denken nicht wie Menschen. Sie sind mathematische Modelle, die mithilfe komplexer Algorithmen lediglich die Illusion von Denken und Sprache erzeugen.
33 Der Inhalt dieses Abschnitts wurde mit Google Gemini 2.5 Pro Preview O3-25 generiert.
34 https://medium.com/@sebuzdugan/thinking-llms-general-instruction-following-with-thought-generation-paper-explained-7cefb01edded
35 https://arxiv.org/html/2410.10630v1
36 https://arstechnica.com/ai/2025/04/researchers-concerned-to-find-ai-models-hiding-their-true-reasoning-processes/
Der Chain-of-Thought (CoT)-Prozess, bei dem ein LLM einzelne Gedankenschritte zusammenstellt, vermittelt den Eindruck, dass das Modell seine Antwort plant und gleichzeitig Annahmen oder Hypothesen überprüft. In manchen Fällen erkennt das Modell sogar eigene Fehler und korrigiert sich selbst. Dieser Ansatz trägt zur Transparenz bei und ermöglicht es, die einzelnen Schritte durch Menschen auf Korrektheit zu überprüfen.
Es wird außerdem behauptet, dass dieser Ansatz das Risiko von Halluzinationen reduziert, da das LLM seine Antwort auf mehreren Wegen prüfen kann, bevor es zu einem Schluss kommt.
Thinking Models eignen sich besonders gut für komplexe, weit gefasste Fragestellungen, die mehrere Fakten oder Hypothesen berücksichtigen müssen. Sie benötigen jedoch mehr Zeit, um auf Prompts zu reagieren, da sie zusätzliche Informationen erzeugen, bevor sie die eigentliche Antwort liefern. Diese Reaktionszeit kann deutlich länger sein, teils mehrere Sekunden mehr als bei einem „nicht-denkenden“ Modell.
Das Unternehmen Anthropic bezeichnet Thinking Models als Simulated Reasoning (SR). In einer veröffentlichten Studie stellte Anthropic jedoch fest, dass SR-Modelle ihre „Denkprozesse“ oft nicht offenlegen.³⁶
Dabei ist es wichtig zu betonen: LLMs denken nicht wie Menschen. Sie sind mathematische Modelle, die mithilfe komplexer Algorithmen lediglich die Illusion von Denken und Sprache erzeugen.

