

1 of 6 - Forging forward with GenAI
10 März 2025


Wicus Ross
Senior Security Researcher
In diesem Abschnitt geben wir einen sehr groben Überblick darüber, was notwendig ist, um große Sprachmodelle (Large Language Models, LLMs) zu entwickeln, eine bemerkenswerte Technologie. Mit einem Blick hinter die Kulissen möchten wir ein besseres Verständnis für die Komplexität und den technischen Anspruch vermitteln, die beim Aufbau und Betrieb eines LLMs erforderlich sind. Dieser Blogbeitrag dient als grundlegende Einführung und ist nicht als Anleitung oder Nachbau dessen gedacht, was Unternehmen wie OpenAI, Google Gemini oder xAI derzeit tun.
Zur Erinnerung: Ein LLM ist ein bedeutender Fortschritt in der Verarbeitung natürlicher Sprache, einem Bereich des maschinellen Lernens und somit Teil der künstlichen Intelligenz. Es ermöglicht Maschinen, mit Menschen in menschlicher Sprache zu interagieren.¹ ²
Das Modell kann Anfragen oder Anweisungen verstehen und auf eine Weise reagieren, die sehr menschlich wirkt, oft mit Eigenschaften, die man Maschinen sonst nicht zuschreiben würde.
Dies ist der Beginn des zweiten Kapitels unserer Blogreihe über generative künstliche Intelligenz. Hier finden Sie Teil 1 und Teil 2 des ersten Kapitels.
Es besteht ein enger Zusammenhang zwischen dem Umfang der Daten, mit denen Sprachmodelle trainiert werden, und den Fähigkeiten sowie der Infrastruktur, die diesen Prozess unterstützen. Der Aufbau eines weltweit führenden LLM erfordert qualifiziertes Fachpersonal mit Expertise in Bereichen wie Data Science, maschinelles Lernen, Hochleistungs-Parallelrechnen, Management großer Rechenzentren und Infrastrukturen und viele weitere technische wie nicht-technische Kompetenzen.
Zwar ist es grundsätzlich möglich, ein Modell auf Hardware in Verbraucherqualität zu entwickeln, doch stößt man dabei schnell an eine klare Leistungsgrenze. Dieser Ansatz eignet sich gut für Bildungszwecke oder erste Prototypen, doch der praktische Nutzen des Endprodukts bleibt begrenzt.
Eine alternative Möglichkeit besteht darin, Rechenleistung von Cloud-Anbietern oder spezialisierten KI-Dienstleistern zu mieten. Allerdings wird auch dieser Ansatz im Vergleich zu Projekten mit dedizierter Hochleistungsinfrastruktur die Leistungsfähigkeit des Modells einschränken.
Für unser weiteres Verständnis gilt: Es braucht mehrere Hardware-Komponenten wie Grafikkarten, die auf parallele Spezialberechnungen ausgelegt sind, sowie eine hohe Kommunikationsbandbreite zwischen diesen Komponenten. Zusätzlich wird eine große Menge an zuverlässigem und schnellem Speicher benötigt.
In dieser Gesprächsreihe werden wir drei Phasen ansprechen, die konzeptionell notwendig sind, um ein großes Sprachmodell (LLM) zu erstellen. Dabei handelt es sich um eine vereinfachte Darstellung eines hochkomplexen Prozesses. Im Groben lassen sich folgende Schritte unterscheiden:
Beeindruckend an der heutigen LLM-Landschaft ist vor allem die Existenz von Open-Source- oder Open-Weight-Modellen. Das gesamte Ökosystem basiert zudem auf einem gut etablierten Set frei zugänglicher Werkzeuge wie etwa PyTorch. Dadurch ist es möglich, die ersten beiden Schritte zu überspringen und direkt in die Anpassung eines bestehenden Modells im Posttraining einzusteigen.
Das senkt die Einstiegshürden erheblich und ermöglicht es Nutzerinnen und Nutzern, Modelle individuell anzupassen. Dennoch ist ein grundlegendes Verständnis der vorherigen Phasen wichtig, da sonst leicht ein Modell mit unerwünschten Eigenschaften entstehen kann.
Ein Beispiel für angepasste LLMs finden Sie im Hugging Face Projekt.
Große Sprachmodelle (LLMs) benötigen Daten in enormem Umfang. Die einfachste Quelle dafür ist das Internet, das systematisch durchforstet und möglichst vollständig heruntergeladen wird. Unternehmen wie OpenAI und Anthropic erklären öffentlich, dass sie diesen Crawling-Prozess so transparent wie möglich gestalten.³ ⁴ Andere hingegen gehen weniger rücksichtsvoll vor und durchsuchen das Netz wahllos, ohne auf die Auswirkungen zu achten. Das belastet vor allem kleinere Webseiten, die sich fast täglich mit Zugriffsmustern konfrontiert sehen, die einem verteilten Denial-of-Service-Angriff ähneln. Die Rechenressourcen der Crawler übersteigen dabei oft die Kapazitäten der betroffenen Webseiten.⁵
Einige Betreiber und Entwickler wehren sich aktiv gegen diese Form automatisierter Datensammlung. Ein Beispiel ist das Projekt Anubis von Xe Iaso, das Zugriffe blockiert, wenn der Besucher keine bestimmte Rechenaufgabe lösen kann. Die Schutzmaßnahme verlangt vom Webbrowser eine sogenannte Proof-of-Work-Aufgabe, also den Nachweis, dass eine gewisse Rechenleistung erbracht wurde. Dazu muss der Browser ein spezielles JavaScript-Programm ausführen, das eine vom System erwartete Antwort liefert. KI-Crawler sind in der Regel nicht in der Lage, diesen Code zu verarbeiten, und werden dadurch effektiv ausgesperrt.⁶
Cloudflare verfolgt einen anderen Ansatz mit seiner Lösung namens AI Labyrinth. Wenn das System einen Daten-Crawler erkennt, erzeugt es automatisch künstliche Webseiten mit gefälschtem Inhalt und leitet den Crawler über interne Verlinkungen immer weiter zu weiteren nichtssagenden Seiten. So wird der Crawler beschäftigt und der Datensatz, den er sammelt, wird bewusst mit nutzlosen Informationen angereichert.⁷
Wer selbst in Betracht zieht, große Datenmengen aus dem Internet zu sammeln, sollte sich darüber im Klaren sein, was genau gesammelt wird und wie aggressiv dieser Prozess abläuft. Es ist wichtig, dabei die geltenden Industriestandards für Webcrawler und deren angemessene Nutzung zu respektieren.⁸
3 https://platform.openai.com/docs/bots
4 https://support.anthropic.com/en/articles/8896518-does-anthropic-crawl-data-from-the-web-and-how-can-site-owners-block-the-crawler
5 https://drewdevault.com/2025/03/17/2025-03-17-Stop-externalizing-your-costs-on-me.html
6 https://xeiaso.net/blog/2025/anubis/
7 https://arstechnica.com/ai/2025/03/cloudflare-turns-ai-against-itself-with-endless-maze-of-irrelevant-facts/
8 https://www.robotstxt.org/
Die KI-Plattform Hugging Face bietet Orientierung für den Prozess der Datensammlung, wie sie im Rahmen ihres FineWeb-Projekts beschrieben ist. Dieses Projekt nutzt Datensätze, die aus dem gemeinnützigen Common Crawl-Projekt stammen.⁹ ¹⁰ Der FineWeb-Datensatz umfasst bereits große Teile des Internets und liegt in tokenisierter Form vor, sodass er direkt für das Training verwendet werden kann.¹¹
Der FineWeb-Datensatz besteht aus 15 Billionen Tokens und benötigt etwa 44 Terabyte Speicherplatz auf der Festplatte.
Dieser Datensatz wurde mithilfe von 96 Snapshots des Common Crawl-Archivs erstellt. Die Version 1.3.0 von FineWeb stammt vom 31. Januar 2025 und berücksichtigt Unterlassungsaufforderungen, indem bestimmte Domains aus dem Datensatz ausgeschlossen werden.¹² Damit werden urheberrechtliche Ansprüche respektiert und rechtlichen sowie regulatorischen Anforderungen entsprochen.
Ein weiterer wichtiger Aspekt: FineWeb bemüht sich ausdrücklich, personenbezogene Daten (PII) aus dem Common Crawl-Datensatz zu entfernen. Der FineWeb-Datensatz wird unter der Open Data Commons Attribution License (ODC-By) Version 1.0 veröffentlicht.¹³
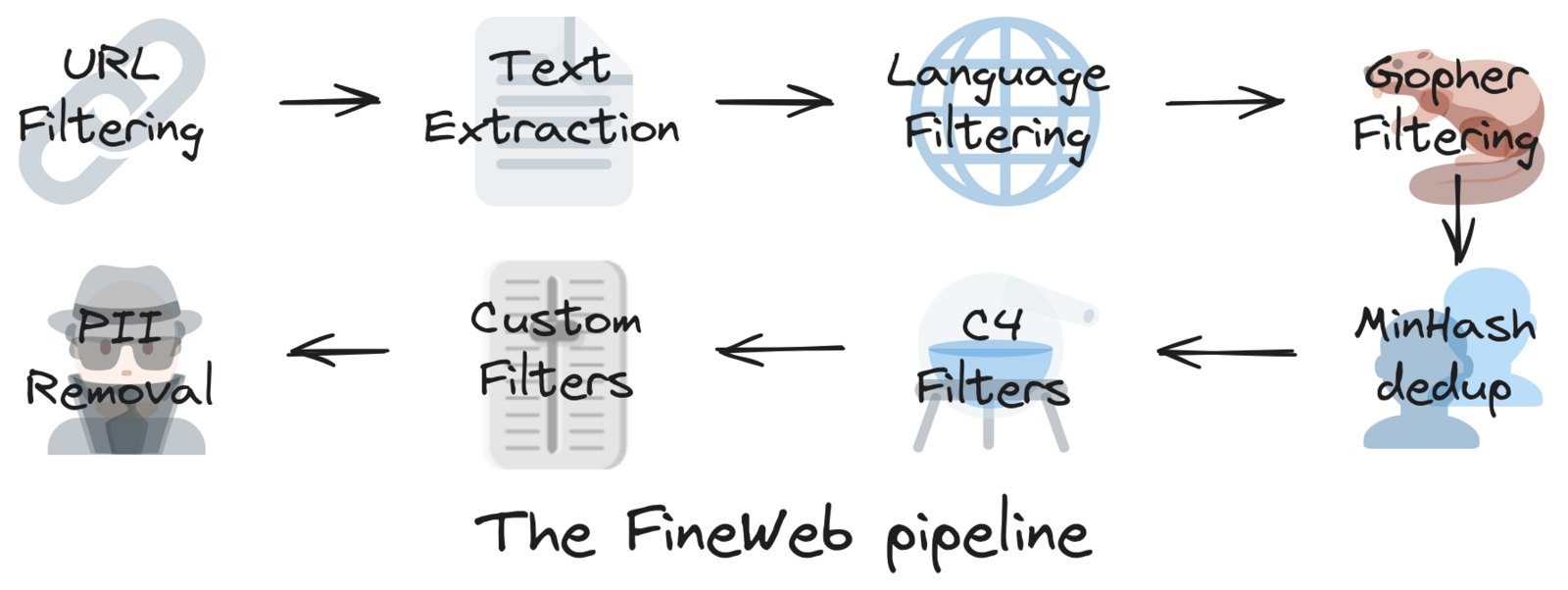
Dies ist ein weiterer Grund, warum die Verwendung eines kuratierten Datensatzes wie FineWeb sinnvoll ist. Er ermöglicht einen sauberen Start, da die Herkunft der Daten, mit denen ein Modell trainiert wird, eindeutig nachvollziehbar ist.
Diese Art von Transparenz wird zunehmend an Bedeutung gewinnen, insbesondere in Anbetracht wachsender Komplexität in der Datenlieferkette sowie im Hinblick auf zukünftige gesetzliche Vorgaben und regulatorische Anforderungen in verschiedenen Rechtsräumen.
Einige Kunden könnten zudem verlangen, dass nachgewiesen wird, dass alle relevanten Gesetze während der Datensammlung und -aufbereitung eingehalten wurden.
9 https://huggingface.co/spaces/HuggingFaceFW/blogpost-fineweb-v1
10 https://commoncrawl.org/
11 https://huggingface.co/datasets/HuggingFaceFW/fineweb
12 https://huggingface.co/datasets/huggingface-legal/takedown-notices/blob/main/2025/2025-01-22-Torstar.md
13 https://opendatacommons.org/licenses/by/1-0/
Tokenisierung ist ein Verfahren aus der Verarbeitung natürlicher Sprache (Natural Language Processing, NLP), bei dem Text in eine numerische Darstellung umgewandelt wird.¹⁴
Diese numerische Repräsentation oder Kodierung ist umkehrbar. Das bedeutet, dass sich aus einer Folge von Tokens wieder die entsprechenden Zeichenfolgen erzeugen lassen, die Wörter oder andere bedeutungsvolle Ausgaben repräsentieren.
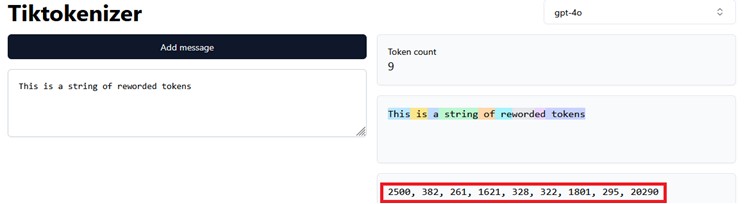
Hier ist eine Visualisierung der Tokenisierung mit der TikTok-Webanwendung. Im Beispiel verwenden wir den GPT-4o-Tokenizer-Algorithmus mit einem Vokabular von 199.997 Token bzw. symbolischen Darstellungen.15 16 Der Satz „Dies ist eine Zeichenfolge umformulierter Token“ ist in 9 Token bzw. Zahlen kodiert, die im roten Rechteck hervorgehoben sind. Die Zuordnung lautet wie folgt:
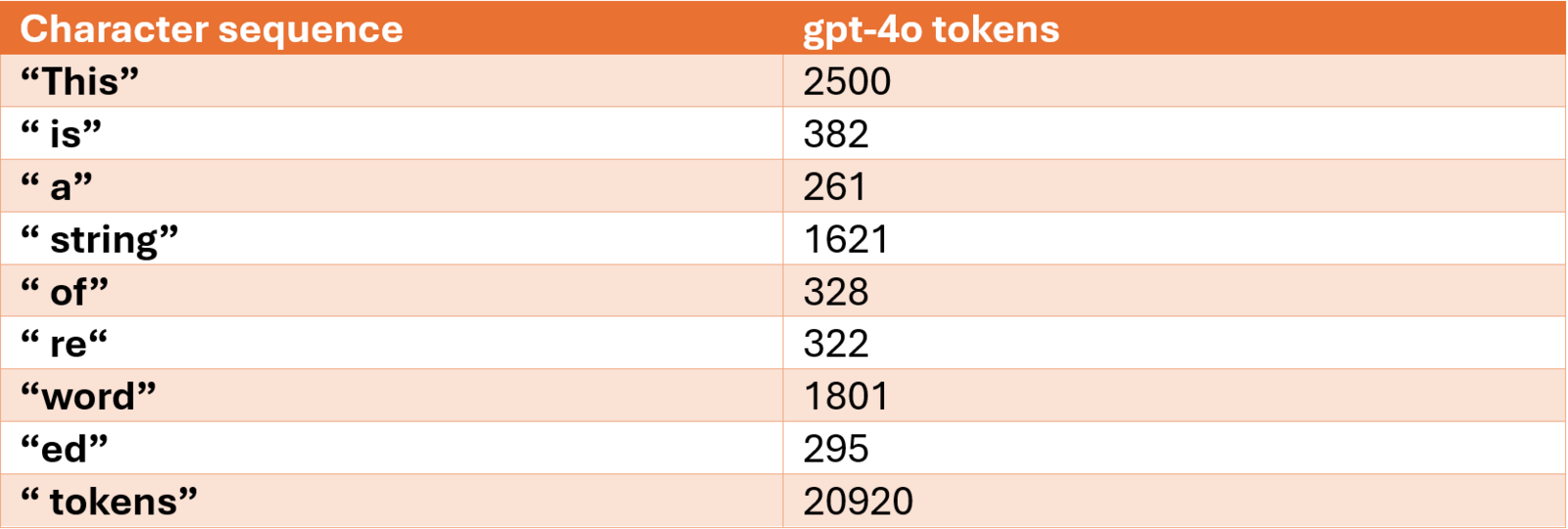
Hinweis: Die Anführungszeichen werden verwendet, um den vorangestellten Leerzeichen-Charakter bei allen Wörtern außer dem ersten zu verdeutlichen. Die Anführungszeichen selbst sind nicht Teil der Token-Zuordnung oder der Sequenz.
Für jedes Vorkommen der Zeichenfolge „ is“ oder „ a“ wird beispielsweise der Token bzw. die Zahl 382 bzw. 261 verwendet, um die jeweilige Zeichenfolge darzustellen.
Bestimmte Zeichenfolgen werden in mehrere Tokens aufgeteilt. So wird zum Beispiel das Wort „reworded“ in die Tokens 322, 1801 und 295 zerlegt. Diese Technik nennt sich Subword-Tokenisierung und wird verwendet, um seltener vorkommende Zeichenfolgen effizienter darzustellen. Dadurch muss nicht für jedes einzelne Wort oder jede Zeichenfolge ein eigener Token im Vokabular hinterlegt werden, was die Größe des Vokabulars reduziert.
Der Vorteil liegt in der Effizienz: Sowohl das Training als auch die Ausführung von großen Sprachmodellen werden dadurch deutlich ressourcenschonender.
Weitere Beispiele für Tokenisierungsverfahren sind Wort-Tokenisierung, Zeichen-Tokenisierung, Byte-Pair-Encoding (BPE), WordPiece-Tokenisierung und Unigram-Tokenisierung.¹⁷ ¹⁸
14 https://www.grammarly.com/blog/ai/what-is-tokenization/
15 https://arxiv.org/html/2406.11214v2
16 https://sebastianraschka.com/blog/2025/bpe-from-scratch.html
17 https://www.datacamp.com/blog/what-is-tokenization
18 https://tokenova.co/tokenization-in-nlp/
Embeddings sind ein zentraler Bestandteil der Verarbeitung natürlicher Sprache (Natural Language Processing, NLP) und gelten als semantisches Rückgrat großer Sprachmodelle (LLMs).¹⁹ Embeddings sind eine besondere Form der Token-Darstellung, bei der semantische Beziehungen mathematisch in einem hochdimensionalen Vektorraum abgebildet werden.
Es gibt verschiedene Arten von Embedding-Algorithmen, darunter Term Frequency–Inverse Document Frequency (TF-IDF), Word2Vec oder BERT. Diese Verfahren können für unterschiedliche Aufgaben im Bereich NLP eingesetzt werden. Bei LLMs ist das Embedding Teil der Eingabeschicht eines neuronalen Netzwerks und wird während des Trainingsprozesses dynamisch angepasst. Dabei werden die kontextuellen Beziehungen zwischen Tokens erfasst, sodass das Modell in der Lage ist, das nächste Token auf Basis der vorherigen korrekt vorherzusagen.
Die Größe des Embedding-Vektors hängt vom jeweiligen Transformermodell ab und beeinflusst sowohl die Genauigkeit als auch die Leistungsfähigkeit des Modells. OpenAIs GPT-2 verwendet zum Beispiel eine Embedding-Größe von 768, während DeepSeek V3 eine deutlich größere Embedding-Größe von 7.168 nutzt.²⁰ ²¹
Da Embeddings so ein wichtiger Bestandteil eines LLMs sind, bieten viele Anbieter sie auch als spezielle API-Funktion an. Diese APIs ermöglichen maßgeschneiderte Embedding-Lösungen, die für bestimmte Branchen und Einsatzszenarien optimiert sind.²² Dies ist ein weiteres Beispiel dafür, wie externe Dienste dabei helfen können, Projekte im Bereich generativer KI gezielt zu beschleunigen oder zu verbessern.
19 https://huggingface.co/spaces/hesamation/primer-llm-embedding?section=dimensionality
20 https://www.alignmentforum.org/posts/BMghmAxYxeSdAteDc/an-exploration-of-gpt-2-s-embedding-weights
21 https://mccormickml.com/2025/02/12/the-inner-workings-of-deep-seek-v3/#:~:text=embedding%20size
22 https://docs.anthropic.com/en/docs/build-with-claude/embeddings
Ein neuronales Netzwerk ist ein statistisches Modell, das in der Lage ist, das nächste Token vorherzusagen, wenn eine Liste von Tokens als Eingabe vorliegt. Es kann aus vielen Schichten miteinander verbundener Knoten bestehen, die eine vereinfachte Nachbildung von Neuronen und Synapsen aus der menschlichen Biologie darstellen.²³
Das Ergebnis ist eine komplexe mathematische Struktur, die aus Parametern besteht, die während des Trainingsprozesses berechnet wurden. Diese Parameterwerte werden als Gewichte bezeichnet.²⁴ ²⁵
Diese Gewichte sind numerische Werte, die den Verbindungen zwischen den Knoten oder „Neuronen“ in den verschiedenen Schichten des Netzwerks zugeordnet sind.
Das mathematische Design des neuronalen Netzwerks muss so gestaltet sein, dass es möglichst ausdrucksstark ist und sich gut für Optimierungen eignet, zum Beispiel für parallele Berechnungen über mehrere Hardware-Cluster hinweg. Dadurch wird Skalierbarkeit ermöglicht und sichergestellt, dass der Trainingsprozess durch zusätzliche Hardware-Ressourcen oder kombinierte Algorithmen verbessert werden kann.
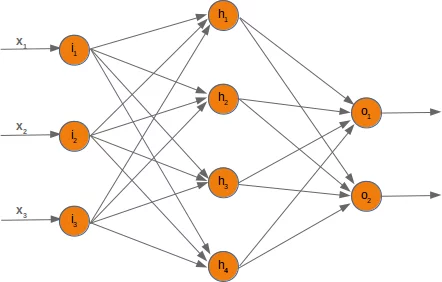
In Abbildung 3 sehen wir ganz links die Eingabeschicht (i), in der Mitte die verborgene Schicht (h) und ganz rechts die Ausgabeschicht (o). Dabei ist zu beachten, dass die verborgene Schicht aus vielen Einzelschichten bestehen kann – was insbesondere auf große Sprachmodelle (LLMs) zutrifft, die Ausgaben wie Text, Bilder, Ton und mehr erzeugen.
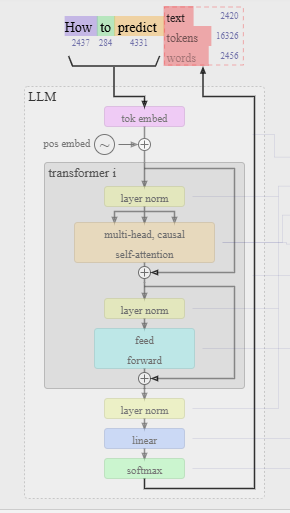
Die Veröffentlichung von OpenAI zu GPT-2 diente als Referenzpunkt zur Definition generativer Sprachmodelle.²⁸ Ein generativer, vortrainierter Transformer (GPT) ist ein spezialisiertes neuronales Netzwerk, das auf mehreren bedeutenden Fortschritten im Design und Aufbau neuronaler Netzwerke basiert, wobei die Transformer-Architektur der jüngste und wichtigste dieser Durchbrüche ist.²⁹ ³⁰
Darüber hinaus waren auch andere Entwicklungen entscheidend für die Architektur moderner GPT-Modelle. Dazu gehören Konzepte wie Multilayer-Perzeptrons (MLP), rekurrente neuronale Netze (RNNs) zur Texterzeugung, Long Short-Term Memory (LSTM), Gated Recurrent Units (GRU) sowie tiefe, feedforward-basierte Convolutional Neural Networks (CNNs) und weitere Ansätze.³¹ ³² ³³ ³⁴ ³⁵ ³⁶
Mehrere Konfigurationselemente bestimmen die Eigenschaften eines neuronalen Netzwerks. Diese werden als Hyperparameter bezeichnet.³⁷ Sie werden vom Entwicklerteam während der Trainingsphase festgelegt. Die Wahl geeigneter Hyperparameter kann verschiedene diagnostische Verfahren erfordern, um durch Testläufe optimale Werte zu bestimmen.
Ein weiterer zentraler Aspekt eines LLM ist das sogenannte Kontextfenster. Es bezeichnet den Textabschnitt – dargestellt als Liste von Tokens – den das Modell nutzt, um den nächsten Token vorherzusagen.³⁸ Das Kontextfenster muss groß genug sein, damit das Modell sinnvolle Vorhersagen treffen kann, darf aber gleichzeitig die Rechenleistung nicht überfordern. Aktuelle Modelle haben sehr große Kontextfenster: GPT-4 zum Beispiel verarbeitet bis zu 128.000 Tokens, Google Gemini 1.5 Pro sogar bis zu 2 Millionen Tokens. Diese Begrenzungen ergeben sich aus der Funktionsweise der Transformerschicht.³⁹
Ein Beispiel: Wenn wir dem neuronalen Netzwerk eine Token-Liste wie
„2500, 382, 261, 1621, 328, 322, 1801, 295“
übergeben, erwarten wir, dass es den nächsten Token „20920“ vorhersagt. Die dekodierte Zeichenfolge daraus lautet:
„This is a string of reworded tokens“.
Damit ein Modell diesen nächsten Token korrekt vorhersagen kann, muss es wissen, mit welcher statistischen Wahrscheinlichkeit dieser Token der passendste nächste Ausdruck ist – in diesem Fall „20920“, das dem Wort „tokens“ entspricht.
Hier finden Sie eine interaktive Darstellung eines generativen Sprachmodells, das Schritt für Schritt visualisiert, wie die Transformer-Architektur funktioniert.
23 https://deepai.org/machine-learning-glossary-and-terms/weight-artificial-neural-network
24 https://deepai.org/machine-learning-glossary-and-terms/neural-network
25 https://python-course.eu/machine-learning/neural-networks-structure-weights-and-matrices.php
26 https://python-course.eu/images/machine-learning/example_network_3_4_2_without_bias.webp
27 https://deepai.org/machine-learning-glossary-and-terms/feed-forward-neural-network
28 https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdfù
29 https://arxiv.org/abs/1706.03762
30 https://poloclub.github.io/transformer-explainer/
31 https://www.jmlr.org/papers/volume3/bengio03a/bengio03a.pdf
32 https://www.fit.vutbr.cz/research/groups/speech/publi/2010/mikolov_interspeech2010_IS100722.pdf
33 https://www.cs.toronto.edu/~jmartens/docs/RNN_Language.pdf
34 https://arxiv.org/abs/1308.0850
35 https://arxiv.org/abs/1409.1259
36 https://arxiv.org/pdf/1609.03499
37 https://deepai.org/machine-learning-glossary-and-terms/hyperparameter
38 https://dataconomy.com/2025/03/04/what-is-context-window-in-large-language-models-llms/
39 https://www.ibm.com/think/topics/context-window
Die Trainingsphase eines großen LLMs besteht darin, die Parameter des Modells auf Grundlage der eingebenden Embeddings anzupassen. Dieser Prozess wird so lange wiederholt, bis der gesamte Trainingsdatensatz durchlaufen wurde. In jeder Schicht des neuronalen Netzwerks werden Berechnungen durchgeführt. Je nach Funktion der jeweiligen Schicht wird entweder Information an vorherige Schichten zurückgegeben oder an die nächste Schicht weitergeleitet. Diese Weitergabe und Rückführung von Informationen führt zur Anpassung der sogenannten Gewichte, also der Parameterwerte des Modells. In besonders großen Modellen kann es sich dabei um Milliarden von Parametern handeln, was das Training bei Datensätzen mit Billionen von Tokens zu einem äußerst rechenintensiven Prozess macht.
Das neuronale Netzwerk bewertet seine Vorhersagegenauigkeit mithilfe einer sogenannten Loss-Funktion. Dabei handelt es sich um eine mathematische Funktion, die misst, wie stark die Vorhersage des Modells vom tatsächlichen erwarteten Ergebnis abweicht.⁴⁰ Anders ausgedrückt: Sie gibt an, wie gut das Modell derzeit darin ist, das nächste Token vorherzusagen – basierend auf dem letzten eingegebenen Kontext.
Wurde das Modell beispielsweise mit dem Satz „This is a string of reworded tokens“ trainiert, nutzt die Loss-Funktion die Eingabe „This is a string of reworded“ und fordert das Modell auf, das nächste Token vorherzusagen. Liefert das Modell korrekt „tokens“, beträgt der Fehlerwert 0. Jeder andere Vorhersagewert führt zu einer Abweichung, die durch die Loss-Funktion numerisch dargestellt wird – je größer die Abweichung von 0, desto ungenauer war die Vorhersage. Dies kann darauf hinweisen, dass eine weitere Trainingsrunde mit denselben Daten oder sogar zusätzliche Trainingsdaten notwendig sind.
Idealerweise sollte sich der Loss-Wert nahe an 0 bewegen, ihn aber niemals vollständig erreichen. Ein Loss-Wert von 0 würde bedeuten, dass das Modell overfitted ist – also die Trainingsdaten zu exakt gelernt hat.⁴¹ Overfitting gilt als Schwäche eines Modells, da es zwar auf dem bekannten Trainingsmaterial hervorragende Ergebnisse liefert, aber bei der Anwendung auf neue, unbekannte Daten versagt. Das Modell hat in diesem Fall keine verallgemeinerbare Kompetenz erlernt, sondern lediglich auswendig gelernt.
Der Pretraining-Schritt eines großen Sprachmodells (LLM) umfasst mehrere wichtige Phasen. Dazu gehört das Sammeln und Aufbereiten der Trainingsdaten, bei dem unerwünschte Inhalte herausgefiltert werden, ebenso wie das Entwerfen einer geeigneten Architektur für das neuronale Netzwerk, die gewünschte Eigenschaften und eine gute Leistungsfähigkeit bietet. Dieser Prozess erfordert zahlreiche Iterationen, das Anpassen von Hyperparametern sowie das kontinuierliche Überwachen der Loss-Funktion, um sicherzustellen, dass das trainierte Modell auch auf echten Daten zuverlässig funktioniert.
Im nächsten Blogbeitrag werfen wir einen Blick auf das Basismodell und die anschließenden Posttraining-Aktivitäten, mit denen sich das LLM weiter verbessern und anpassen lässt.
Teil 4 wird nächste Woche veröffentlicht.

