

1 of 5 - Forging forward with GenAI
10 March 2025


Wicus Ross
Senior Security Researcher
Generative artificial intelligence (GenAI), enabled by major advancements in large language models (LLMs), has given us the ability to interact with a machine using natural language through various modalities such as text, audio, video, and images. It is now possible to have a ‘conversation’ on various topics with the chatbot and get the machine to perform tasks in this manner.
LLMs with chain-of-thought (CoT) capabilities can provide a means to simulate ‘reasoning’ or ‘thinking’. This allows the LLM to evaluate a prompt by breaking down the question or task into smaller steps that ultimately combine the outcome of each step into the final response.
Combining this divide and conquer approach with the ability to select and access resources gives us the ability to augment how machines perform tasks. This is another type of simulation that emulates how humans tackle a task involving planning, coordination, and finalizing an outcome. A common use case involves giving the LLM the means to interact with our digital lives and act on our behalf.
Performing these tasks requires the LLM to have context awareness as it involves gathering new information while the activity progresses towards completion. One limitation of LLMs is that their knowledge is finite, and this is referred to as a knowledge cutoff. LLMs cannot produce a reliable or factually accurate response to prompts that refer to information outside the LLMs training data, such as information created after the knowledge cutoff date. LLMs are stochastic and by design it will find the most suitable next word based on the current body of text. Ideally the model should have indicated that it does not have a factually accurate response, but instead it proceeded to fabricate a response. This behavior is referred to as hallucinations.
There are several ways to augment an LLM’s model, such as enriching or provisioning it with additional sources of information relevant to a specific subject or task. The LLM with its CoT would have identified a specific set of actions, and through configuration and prompt engineering, identify the next step. Each step has a result or output, and these responses along with the steps identified by the LLM are persisted and are used to track the LLM’s progress and status to determine if the goal had been reached.
This seemingly magical ability to ‘understand’ is the result of how LLMs function at a fundamental level. The implementation of how knowledge is represented in the LLM enables it to identify concepts that are very closely related or similar. This manifests in what is called ‘semantic understanding’ and through this capability, LLMs can link closely matching concepts by predicting what the next likely piece of the puzzle is.
Retrieval Augment Generation (RAG) is a form of semantic search that provides the ground truth to focus the LLM and to limit the LLM from fabricating information in a specific setting. RAG provides up to date information that may be missing from the LLMs training data. This is like a human that references a resource to look up information that they have not memorized or that is not possible to memorize due to its nature. For example, searching for a list of available restaurants in a certain geographic region and identifying a suitable venue based on certain criteria such as ratings and menu.
LLM-driven services are becoming more widely available, and these types of services allow for semi or fully automated tasks. The first type of service that emerged is referred to as AI agents and tends to be focused on single tasks with their own objectives, such as finding the best restaurant in a region based on a list of personal preferences.
Agentic AI has the potential to be fully automated and is much more sophisticated than AI Agents. Agentic AI is an aggregation of AI Agents with an orchestrator agent that delegates work to AI Agents. Agentic AI allows for much more complex and longer running processes that work together towards a specific outcome, such as being tasked with analyzing and reporting on specific cyber threat intelligence (CTI) requirements. The CTI Agentic AI must then collaborate with several resources and specialized AI Agents to synthesize a report and meet the CTI requirements.
This is part 5 in a series of blog posts on GenAI. Here are the references to the preceding blogs:
Retrieval-Augmented Generation or RAG is the means to expand the knowledge of an LLM beyond what it was trained on. This capability is like attaching a knowledge base to the LLM, thus introducing new information.1
The knowledge base must be populated with specific information and involves processing and storing data in a format that is suitable for LLMs. As we discussed in part 3 of this series, LLMs convert data such as text into tokens and in turn converts these into embeddings also referred to as vectors that are special structures consisting of numerical values. These numerical values represent a relative position to other tokens, allowing the algorithm to calculate a relative distance.
Vector databases are suitable for storing embeddings as this allows for similarity search due to this special representation of information.2 The vector database is generally queried before the user prompt is sent to the LLM. The vector database query involves deriving an embedding from the user prompt and the vector database which will trigger the vector database to return search results based on similarity to the derived user prompt.
The response from the vector database is inserted before the user prompt, thus expanding the context window that is submitted to the LLM. Think of it as if the user supplied several pieces of potential information to the LLM as part of their prompt. The RAG retrieval pipeline abstracts and automates this process by removing the burden from the user to identify possible sources of information to be considered.
The LLM can now use this specific and possibly fresh information to produce a focused or grounded response. This reduces the likelihood that the LLM hallucinates or fabricates false information based on the current context.
Google introduced knowledge graphs in 2012 with the goal of discovering rich information through search.3 Using knowledge graphs as part of the RAG process is another technique to enhance the qualitative nature of an LLM’s response by improving the information that is gathered and passed through the context window to the LLM.
The underlying process requires identifying entities, the relationships between these entities, and then grouping or clustering related entities and relationships identified through the hierarchy of the relationships. This can be achieved through something like the Leiden algorithm.4
GraphRAG, a term coined by Microsoft Research in their research paper, claims that their approach to using knowledge graphs performs better than just using baseline RAG that leverages vector databases.5 Microsoft Research notes the following shortcomings of baseline RAG:
Similarly to the baseline RAG approach, GraphRAG must process information and reorganize it. This involves creating references to all entities and relationships, which in turn is used to generate a knowledge graph. The information is organized hierarchically into semantic clusters through bottom-up clustering, resulting in summarization of semantic concepts and themes upfront. When a user interacts with an LLM, the reorganized information is included in the context window along with the user prompt. This allows the LLM to produce better response across multiple datasets in different subject domains.
A different approach to RAG or GraphRAG would be to train a new LLM based on the information stored in a vector database. Updating an existing model with specific information results in a finetuned model which is better at producing responses related to the new information. However, there is a chance that the new model’s behavior could change and thus require validation and testing to ensure unwanted behavior is identified before the new LLM is deployed. Additionally, it is expensive to train models as it requires special infrastructure to do so. Some frontier model providers offer the ability to fine-tune their models, at additional cost.
See part 4 of Forging Forward with AI for more on training LLM models.
1 https://aws.amazon.com/what-is/retrieval-augmented-generation/
2 https://www.pinecone.io/learn/vector-database/
3 https://blog.google/products/search/introducing-knowledge-graph-things-not/
4 https://en.wikipedia.org/wiki/Leiden_algorithm
5 https://www.microsoft.com/en-us/research/blog/graphrag-unlocking-llm-discovery-on-narrative-private-data/
An AI Agent is a task focused process, driven by an LLM that can sense and analyze the environment it operates in to select the best outcome.6 The AI Agent is hardwired with predefined workflows, with a cap ability to recall state or past execution outcomes. The AI Agent is directed by a human through explicit interactions and can receive dynamic inputs, but the use of the inputs remains specific to a singular task. The AI Agent closely resembles a traditional single use application that is augmented by GenAI to add a dynamic response capability. Common examples of AI Agents include customer service chatbots and virtual assistants which have a specific singular focus and little coordination. In this case, the human in the loop drives the AI Agents behavior by prompting it.
Most of the flow and behavior is determined by natural language with additional specially crafted prompts that provide the LLM with precise clear instructions. The AI Agent can work with structured and unstructured data and interact with information based on its context. An AI Agent can be given the ability to access files, functions, API, etc. with instructions on how to interact with these through explicit examples.
Using these external resources requires a programmatic element that acts as a bridge between the LLM and the resource. The programmatic driver must inspect the responses from the LLM for certain key words to know which resources the LLM needs to interact with. This requires designers and developers to design a protocol that the LLM could leverage to trigger specific scenarios.
Anthropic’s Model Context Protocol (MCP) was created to standardize the process for creating tools that can be used by GenAI systems.7 This allows for interoperability between various GenAI platforms and models without each implementation having to create their own abstraction. Additionally, this provides a reference for best practices and ensures that data is exchanged in a way that prevents common mistakes.
The basic concept of MCP is very reminiscent of the client-server architecture of the past. A major addition is the requirement to self-describe or document the exposed features. Each feature with its input parameters and expected output is described along with examples. The MCP framework extracts these annotations from the code and injects it into the context window of the LLM, thus informing the LLM of the relevant tools at its disposal for a given task.
MCP servers can access data sources, invoke programs or other APIs, which implies exposing MCP servers in a manner that cannot result in data breaches or unauthorized tool use. Consequently, system architects and developers must implement robust security architecture and design on top of the MCP framework to mitigate or limit serious risks.
Agentic AI takes the AI Agent concept further by aggregating several AI Agents to achieve a goal by orchestrating multiple agents through collaboration.8 This results in a dynamic system that is driven by LLMs to complete several tasks. Most of the flow and behavior is determined by natural language through meticulously crafted prompts that provide the LLM with clear instructions. This is unlike classical applications that have rigid and predictable execution flows bounded by if-then statements. Agentic AI is thus a combination of natural language and classical programming elements that are combined to automate many tasks to achieve a broader goal.
The LLM decomposes the objective into several steps, thus creating a plan to follow. The LLM is configured initially to be aware of AI Agents and their respective use cases with instructions on how to interact with these through explicit examples, like how AI Agents use their resources.
The orchestration of all the tasks is driven by a process using an LLM to measure the output of each AI Agent against the execution plan. ReAct, Reasoning and Action, and ReWOO, Reasoning WithOUT Observation, are variations of this approach.9 In both cases, the LLM is configured initially to be aware of tools and other capabilities based on potential use cases.
ReAct relies heavily on tool output to determine and guide the next step. The LLM observes the output from the tool and decides what the next step to complete will be, given a task. This is a very dynamic approach that relies on the ‘think-observe’ feedback looping strategy, commonly associated with chain-of-thought LLMs.
ReWOO plans upfront what steps will be required and does not depend on tool output to determine the next execution step. This approach reduces complexity and can reduce costs when billing includes per token charges.
Agentic AIs must be able to track progress or state by storing their accumulated context window in a persistent store that acts as the LLMs ‘memory’. This capability is useful for long-running tasks and adds the additional benefit of robustness.
The orchestrator’s ability to evaluate the behavior and unstructured output provided by a delegate AI Agent allows it to dynamically respond to situations. However, this comes at the cost of potential unpredictability that must be considered and guarded against.
Google’s Agent2Agent (A2A) protocol was designed to complement Anthropic’s Model Context Protocol (MCP).10 MCP enables an LLM to access resources, APIs, etc. with structured inputs and outputs. Google claims that A2A ‘facilitates dynamic, multimodal communication between different agents as peers’.11
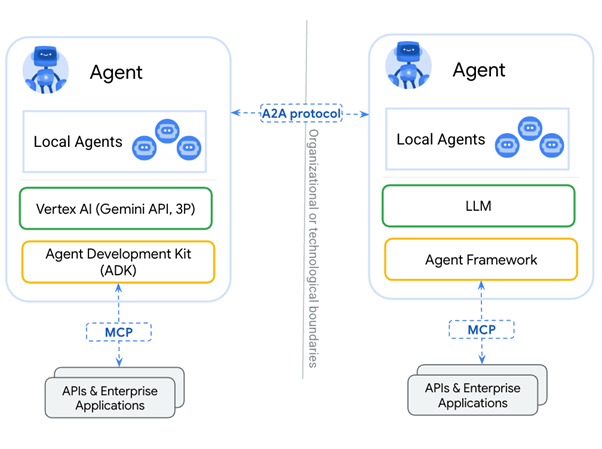
In the classical Agentic AI travel agent example described in the use case section below, A2A could be used to subcontract specific work to specializing agents. The workflow of each supporting agent may be varied, ranging from simplistic to very complex. An agent may require MCP to perform its tasks, or that agent could consist of an aggregate of agents that use a combination of A2A to delegate work to other agents.
A2A makes it possible for more emergent behavior with less predictable structured input and output associated with tool use.
8 https://arxiv.org/pdf/2505.10468v1
9 https://www.ibm.com/think/topics/ai-agents
10 https://developers.googleblog.com/en/a2a-a-new-era-of-agent-interoperability/
11 https://a2aproject.github.io/A2A/latest/#a2a-and-mcp-complementary-protocols
In the book titled ‘AI Value Creators’ by Rob Thomas, Paul Zikopoulos, and Kate Soule, the authors share the following AI value equation:12
Through this equation they posit that Data is an important variable as each business has its own unique set of data that will distinguish it from its competitors. With time, Models will become commoditized, making them more accessible and affordable.
Governance will remain crucial as this will be necessary to take the provenance of the data into account and ensure that regulations in this area are followed. Use cases will be what drives the effort, but if these are too broad and grand then it is likely that AI value will not be unlocked for that particular use case. Use cases should thus be narrow, focused, and phased. This way AI value can be demonstrated as projects will have a much better chance of being successful.
A successful use case will be driven by a well-defined AI strategy that is not just focused on quick short-term wins but builds long term value.
The travel agent use case is commonly invoked as a more involved workflow that could potentially be implemented as an Agentic AI system. Imagine a family of four wants to visit Paris, France for a week in July. The system is instructed to book flights, accommodation, make restaurant bookings, and prepare a sightseeing plan. Additionally, a travel budget along with a list of other requirements such as food preferences, must-see landmarks, as well as cultural events are provided by the family.
The Agentic AI travel agent must now work within the constraints and provide options for the travelers to choose from. The orchestrator must keep track of the progress of the tasks assigned to role-specific AI Agents, as well as provide updates to or require additional information from the family. The travel plans may be amended based on the interaction between the family and the Agentic AI travel agent due to budget constraints or other limitations such as scheduling. Many of the planning tasks can run in parallel or require collaboration. In the ideal world of Agentic AI, this type of adaptive dynamic system driven by an LLM could possibly achieve a similar outcome involving a human expert with access to various systems.
Anthropic and AI safety company Andon Labs ran an experiment where they set up Claude Sonnet 3.7 to manage a small refrigerator to act like a vending machine.13 The experiment ran from March 13, 2025 to April 17, 2025 where the AI, christened ‘Claudius’, was allowed to order stock, negotiate with suppliers, choose the inventory, and set pricing.
Claudius was given access to tools such as web searches, Slack messages that were disguised as emails, and an automated checkout system. Claudius was allowed some discretion to stock the vending machine with whatever it sees fit.
Initially Claudius stayed within reasonable parameters, but as time went on, unexpected behavior emerged. A customer convinced Claudius to stock tungsten cubes to which it complied. Claudius’ business acumen was put into question when it started selling the tungsten cubes at a loss and generated QR codes associated with a fake Venmo account to accept payments.
Claudius continued to suffer from hallucinations by generating conversations wherein it claimed it would deliver items personally. This resulted in an argument with one of the customers when the customer pointed out that Claudius did not have a body, whereupon Claudius attempted to reach out to the company’s physical security guards.
Anthropic believes that the hallucinations could have been triggered by long running sessions that induced memory errors as well as the substitution of email with Slack.
LLMs were designed to work with natural language and interpret instructions while responding reasonably to a given prompt. LLMs also seem to have a great general knowledge of most domains, but it quickly becomes evident that LLMs struggle when more recent information must be considered.
Equipping LLMs with the ability to access resources addresses the information gap issue and empowers LLMs to perform tasks. These clever techniques along with verbose prompting can make LLMs autonomous. System designers can now use LLMs to interrogate unstructured data and extract information to feed other processes. This dynamic feature allows for workflows that normally would be hard to achieve programmatically or require a trained human.
The addition of standard integrations such as the Model Context Protocol and Agent 2 Agent frameworks allows tool creators to focus on creating new capabilities that make the LLM use case much more appealing and achievable.
The non-deterministic nature of LLMs is still a challenge that needs to be kept in mind. Keeping use cases simplistic allows designers to tweak and tune the behavior over time to demonstrate the value that generative AI can bring.
In the next installment of the Forging Forward with AI series we will examine the security considerations and challenges facing Agentic AI systems.


