

10 maart 2025 | Blog

We geven in dit blog een beknopt overzicht van wat er komt kijken bij het bouwen van large language models (LLM’s), een indrukwekkende technologie. Door een stukje van het gordijn opzij te schuiven, laten we iets zien van de complexiteit en verfijning die nodig zijn om een LLM te ontwikkelen en te onderhouden. Dit artikel is bedoeld als introductie, niet als stappenplan om na te doen wat bedrijven als OpenAI, Google Gemini of xAI doen.
Ter herinnering: een LLM is een doorbraak op het gebied van natural language processing (NLP) en machine learning (ML), beide onderdeel van artificial intelligence (AI). Deze technologie maakt het mogelijk dat een machine met mensen communiceert in menselijke taal. Zie ook de uitleg van IBM en Wikipedia.
Zo’n machine kan verzoeken of instructies begrijpen en reageren op een manier die verrassend menselijk aanvoelt. Daarbij vertoont het gedrag dat we normaal niet aan technologie toeschrijven.
Dit is het begin van het tweede hoofdstuk in onze blogreeks over Generative AI (GenAI).
Er is een sterke samenhang tussen de hoeveelheid data die wordt gebruikt om modellen te trainen en de vaardigheden en infrastructuur die dat mogelijk maken. Het bouwen van LLM’s van wereldklasse vraagt om gespecialiseerde mensen met kennis van data science, machine learning, high-performance parallel computing, beheer van grote datacenters en infrastructuur, en nog veel meer technische én niet-technische vaardigheden.
Het is technisch gezien mogelijk om een model te bouwen met consumentenhardware, maar dat kent duidelijke beperkingen. Zo’n model is prima voor educatieve doeleinden of voor een eerste prototype, maar de uiteindelijke functionaliteit blijft beperkt.
Een alternatief is om rekenkracht te huren via cloudproviders of gespecialiseerde AI-diensten. Ook dat helpt je een eind op weg, maar het eindresultaat zal meestal niet op kunnen tegen modellen die zijn gebouwd met eigen high-end infrastructuur.
Voor ons verhaal is het belangrijk om te weten dat je meerdere hardwaremodules nodig hebt, zoals grafische kaarten die gespecialiseerd zijn in parallelle berekeningen. Tussen die modules moet veel en snelle communicatie mogelijk zijn. Daarnaast is er ook behoefte aan veel, betrouwbare en snelle opslagruimte.
In deze blogreeks bespreken we drie fasen die conceptueel nodig zijn om een LLM te bouwen. We houden het bewust eenvoudig – in de praktijk is het proces natuurlijk veel complexer. In grote lijnen zijn er drie stappen:
Pre-training
Het maken van een basismodel (bespreken we in de volgende blogpost)
Post-training (ook in de volgende blogpost)
Wat het huidige LLM-landschap zo bijzonder maakt, is de beschikbaarheid van open-sourcemodellen of modellen met open gewichten. Daarnaast draait het ecosysteem om een goed gedefinieerde set tools die vrij beschikbaar zijn, zoals PyTorch. Hierdoor kun je de eerste twee stappen overslaan en direct aan de slag met het aanpassen van een bestaand model in de post-trainingfase.
Dit verlaagt de instapdrempel en maakt het mogelijk om een model aan te passen naar eigen inzicht. Het vereist echter wel kennis van de eerdere stappen. Zonder die kennis loop je het risico om een model te maken met ongewenste eigenschappen.
Een goed voorbeeld van aangepaste LLM’s vind je op het Hugging Face-project.
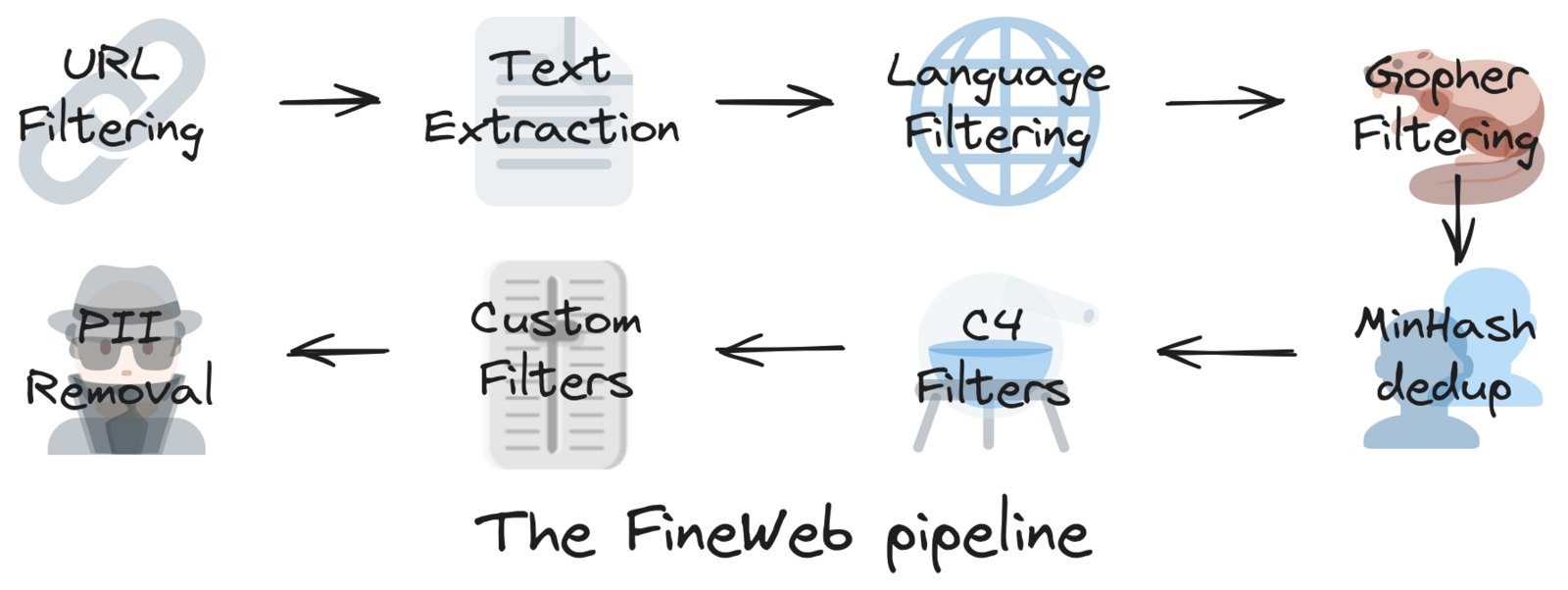
Deze eerste stap bestaat uit verschillende samenhangende activiteiten. Er is data nodig om het model te trainen, en zowel de kwaliteit als de hoeveelheid van die data zijn bepalend voor wat het model uiteindelijk kan. Hiervoor wordt doorgaans een proces opgezet dat het internet afstruint om content te verzamelen. Die verzamelde data moet vervolgens worden opgeschoond: ongewenste of dubbele inhoud wordt verwijderd, auteursrechtelijk beschermd materiaal wordt uitgesloten, en bijvoorbeeld alleen Engelstalige teksten blijven over.
De opgeschoonde dataset wordt daarna omgezet in een speciale codering, een proces dat tokenisatie wordt genoemd. Hierbij worden woorden en veelvoorkomende tekens of lettercombinaties vertaald naar numerieke representaties, wat resulteert in een reeks getallen. Een specifieke vorm van tokenisatie, embeddings, legt daarbij ook semantische relaties tussen tokens vast. Zo krijgt het model context en betekenis mee.
Daarna volgt de daadwerkelijke training van het model. Dit vereist het configureren van een algoritme dat verantwoordelijk is voor het bouwen van het model. Zo’n algoritme – ook wel een neuraal netwerk genoemd – bestaat uit meerdere componenten die berekeningen uitvoeren. Die berekeningen bepalen zogenoemde gewichten, oftewel numerieke waarden die het model sturen bij het genereren van antwoorden op gebruikersinput.
Het model wordt vervolgens geëvalueerd om te bepalen of het geschikt is voor het beoogde doel. Als dat nog niet het geval is, worden er aanpassingen gedaan en volgt een nieuwe trainingsronde. Deze pre-trainingfase stopt zodra het model aan de gestelde eisen voldoet. Het resultaat is dan het basismodel.
Large language models (LLM’s) hebben data nodig. Véél data. De makkelijkste bron is simpelweg het internet: alles afstruinen en downloaden wat los en vast zit. Bedrijven als OpenAI en Anthropic geven aan dat ze dit zo transparant mogelijk proberen te doen. Maar er zijn ook partijen die zonder scrupules alles opzuigen wat ze kunnen vinden. Dat heeft gevolgen.
Vooral kleinere websites hebben hier last van. Zij krijgen dagelijks te maken met wat voelt als een distributed denial of service (DDoS)-aanval, omdat de crawlers veel meer servercapaciteit gebruiken dan deze websites aankunnen (bron).
Sommige ontwikkelaars en platforms slaan terug tegen deze AI-scrapers. Een voorbeeld is het project Anubis van Xe Iaso. Die oplossing blokkeert toegang als de bezoeker niet in staat is om een speciale berekening uit te voeren. Dit werkt via een zogeheten proof of work, een taak die alleen moderne webbrowsers kunnen uitvoeren. De browser moet via JavaScript een specifieke waarde berekenen. AI-scrapers kunnen die taak niet voltooien en worden daarom automatisch geweigerd.
Cloudflare kiest een andere route met hun AI Labyrinth-oplossing. Als hun systeem een scraper detecteert, krijgt die fictieve content voorgeschoteld, inclusief links naar meer nepinhoud. De scraper wordt zo op een dwaalspoor gezet en eindigt met een dataset vol onzin. Effectief vergiftigen ze hiermee het resultaat van de scraper.
Wie besluit om het internet grootschalig te gaan crawlen, moet zich bewust zijn van wát er verzameld wordt en hoe agressief dat gebeurt. Houd rekening met de geldende normen voor webcrawlers en de richtlijnen voor verantwoord gebruik, zoals die worden beschreven op robots.txt.
Het AI-platform Hugging Face biedt richtlijnen voor het verzamelen van data via hun FineWeb-project, dat gebruikmaakt van datasets afkomstig van het non-profitinitiatief Common Crawl. De FineWeb-dataset bevat inmiddels een groot deel van het internet en is al getokeniseerd en dus klaar voor training (bron).
De dataset bestaat uit 15 biljoen tokens en neemt ongeveer 44 terabyte aan opslagruimte in beslag.
Deze set is opgebouwd uit 96 snapshots van Common Crawl. Versie 1.3.0 van FineWeb dateert van 31 januari 2025 en houdt zich aan cease and desist-verzoeken, waarmee bepaalde domeinen op verzoek uit de dataset zijn verwijderd (bron). Dit gebeurt om auteursrechten te respecteren en te voldoen aan juridische en compliancevereisten.
Belangrijk is ook dat FineWeb actief probeert om persoonsgegevens (personally identifiable information, PII) uit de dataset te filteren. De dataset wordt vrijgegeven onder de Open Data Commons Attribution License (ODC-By) v1.0.
Dit is nog een reden waarom het gebruik van een samengestelde dataset zoals FineWeb je helpt om schoon te starten, doordat de herkomst van de gebruikte data duidelijk is. Die transparantie wordt steeds belangrijker naarmate de dataketen drukker wordt, en met het oog op toekomstige wetgeving en compliance-eisen in verschillende rechtsgebieden. Sommige klanten kunnen zelfs vragen om bewijs dat de wetgeving is nageleefd tijdens het verzamelen en voorbereiden van de data.
Meer over de bronnen:
FineWeb-project van Hugging Face: link
Common Crawl: link
Voorbeeld van een takedown notice: Torstar-verwijderverzoek
Licentie: Open Data Commons Attribution License (ODC-By) v1.0
Tokenization is een natural language processing (NLP)-techniek waarbij tekst wordt omgezet in een numerieke representatie (bron). Die numerieke representatie – of codering – is omkeerbaar. Dat betekent dat je een reeks tokens weer kunt terugvertalen naar de oorspronkelijke tekens, woorden of andere betekenisvolle output.
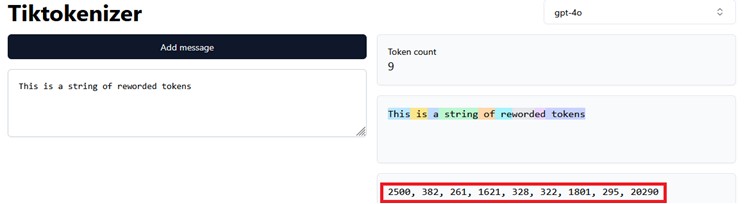
Hier zie je een visualisatie van tokenisatie via de Tiktokenizer webapp. In dit voorbeeld gebruiken we het tokenizer-algoritme van GPT-4o, dat een vocabulaire heeft van 199.997 tokens, oftewel symbolische representaties (bron, bron).
De zin “This is a string of reworded tokens” wordt hierbij gecodeerd tot 9 tokens, oftewel getallen, die in de visualisatie zijn gemarkeerd met een rood kader. De mapping is als volgt:
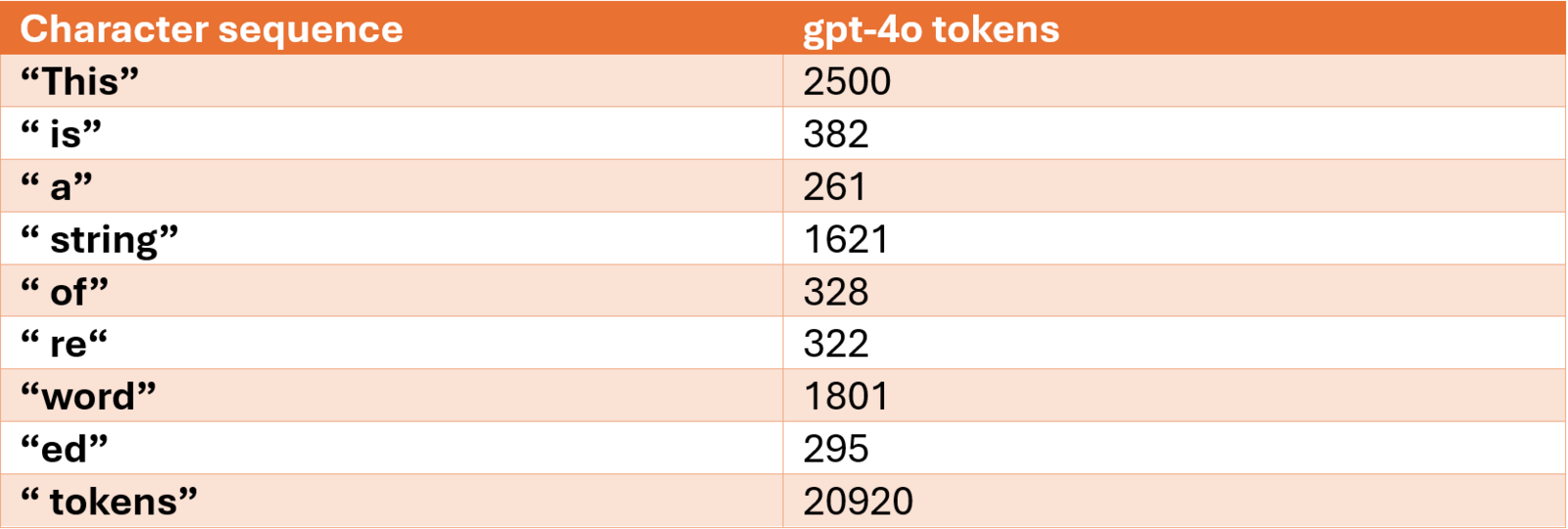
Let op: de aanhalingstekens in het voorbeeld worden alleen gebruikt om het spatiekarakter vóór elk woord (behalve het eerste) te laten zien. Ze maken géén onderdeel uit van de tokenreeks of de mapping.
Voor elke keer dat de tekenreeks " is" of " a" voorkomt, wordt respectievelijk token/nummer 382 of 261 gebruikt om die reeks weer te geven. Sommige tekenreeksen worden opgesplitst in meerdere tokens. Zo wordt bijvoorbeeld “reworded” gecodeerd als 322, 1801 en 295. Deze aanpak heet subword tokenization en wordt toegepast voor minder vaak voorkomende tekencombinaties. Het voordeel hiervan is dat je met een veel kleinere vocabulaire kunt werken, omdat niet elke woord- of tekencombinatie een unieke token hoeft te krijgen.
Dat maakt het trainen en gebruiken van LLM’s een stuk efficiënter.
Andere vormen van tokenisatie zijn onder andere:
word tokenization
character tokenization
byte pair encoding (BPE)
WordPiece tokenization
unigram tokenization
Meer informatie:
Embeddings vormen een belangrijk onderdeel van natural language processing (NLP) en worden gezien als de semantische ruggengraat van LLM’s (bron). Het is een speciale vorm van tokenisatie waarbij woorden of tokens worden weergegeven als vectoren in een hoog-dimensionale ruimte. Die vectoren leggen wiskundig vast hoe tokens zich semantisch tot elkaar verhouden.
Er bestaan verschillende embedding-algoritmes, zoals Term Frequency–Inverse Document Frequency (TF-IDF), Word2Vec, BERT en meer. Deze technieken worden toegepast in uiteenlopende NLP-toepassingen. In het geval van LLM’s maakt de embedding deel uit van de inputlaag van een neuraal netwerk, en wordt deze tijdens het trainen aangepast. Zo kan het model de contextuele relatie tussen tokens vastleggen en voorspellen welk token logisch volgt op de voorgaande.
De grootte van de embeddingvector verschilt per transformermodel en heeft invloed op zowel de nauwkeurigheid als de prestaties van het model. Zo heeft OpenAI’s GPT-2 een embedding size van 768, terwijl DeepSeek V3 werkt met een embeddinggrootte van 7.168.
Omdat embeddings zo’n fundamentele rol spelen binnen LLM’s, worden ze ook aangeboden als gespecialiseerde API-diensten. Hiermee kun je aangepaste embeddings genereren die zijn geoptimaliseerd voor specifieke sectoren of toepassingen (bron: Anthropic). Dit is opnieuw een voorbeeld van hoe externe diensten kunnen helpen om je GenAI-traject te versnellen of te verbeteren.
Een neural network is een statistisch model dat op basis van een reeks tokens als input het volgende token kan voorspellen. Zo’n netwerk bestaat uit meerdere lagen van met elkaar verbonden knooppunten – een vereenvoudigde weergave van neuronen en synapsen zoals we die kennen uit de biologie (bron). Dit levert een wiskundige structuur op die bestaat uit parameters die tijdens de training zijn berekend. Die parameters noemen we gewichten (bron, bron).
Die gewichten zijn numerieke waarden die horen bij de verbindingen tussen knooppunten (of ‘neuronen’) in elke laag van het netwerk.
De opbouw van de wiskundige vergelijkingen die het netwerk vormen, moet krachtig en tegelijk geschikt zijn voor optimalisatie. Denk aan uitvoering over meerdere hardwareclusters tegelijk. Dit maakt schaalbaarheid mogelijk en zorgt ervoor dat het trainingsproces kan worden versneld of verbeterd door extra rekenkracht toe te voegen of slimme algoritmes met elkaar te combineren.
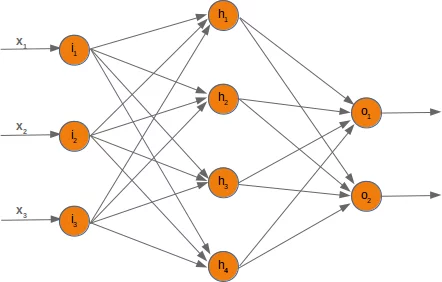
In figuur 3 zie je links de inputlaag (i), in het midden de verborgen laag (h), en rechts de outputlaag (o). Let op: de verborgen laag kan uit meerdere lagen bestaan. Dat geldt zeker voor LLM’s die output genereren zoals tekst, afbeeldingen of geluid.
De GPT-2-paper van OpenAI wordt vaak als referentie gebruikt voor het definiëren van generatieve LLM’s. Een generative pretrained transformer (GPT) is een gespecialiseerd neuraal netwerk dat voortbouwt op diverse doorbraken in het ontwerp van neurale netwerken. De meest recente en invloedrijke is de transformer-architectuur.
Daarnaast zijn er nog andere belangrijke bouwstenen geweest die de GPT-architectuur mogelijk maakten, zoals:
multilayered perceptron (MLP)
recurrent neural networks (RNNs)
long short-term memory (LSTM)
gated recurrent unit (GRU)
feedforward convolutional neural networks (CNNs)
Bronnen en uitleg:
CNNs – DeepAI
Er zijn verschillende instellingen die bepalen hoe een neuraal netwerk zich gedraagt. Deze variabelen worden hyperparameters genoemd (bron). Ze worden gekozen door de makers van het model tijdens de trainingsfase. Het bepalen van de optimale hyperparameters vereist vaak meerdere tests en afstemmingen.
Een andere belangrijke eigenschap van een LLM is het contextvenster. Dit venster bestaat uit een reeks tokens en vormt de context die het model gebruikt om te voorspellen wat er daarna komt (bron). Het contextvenster moet groot genoeg zijn om zinvolle voorspellingen te doen, zonder dat het te zwaar wordt qua rekenkracht. Bij GPT-4 kan dit oplopen tot 128.000 tokens, terwijl Google Gemini 1.5 Pro werkt met een venster tot 2 miljoen tokens. Deze limieten worden opgelegd door de transformerlaag van het model.
Stel dat we het netwerk de volgende tokenreeks aanbieden:
“2500, 382, 261, 1621, 328, 322, 1801, 295”
Dan verwachten we dat het model het volgende token voorspelt als “20920”. Wanneer we deze reeks decoderen, krijgen we: “This is a string of reworded tokens”. Om dat volgende token correct te kunnen voorspellen, moet het model weten wat de statistische kans is dat “20920” (oftewel het woord “tokens”) het meest logische vervolg is.
Bekijk hier een interactieve visualisatie van een generatieve LLM, waarin stap voor stap wordt uitgelegd hoe de transformerarchitectuur werkt.
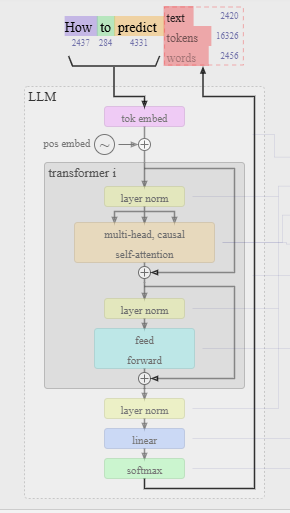
De transformerarchitectuur is een van de meest invloedrijke innovaties binnen de ontwikkeling van LLM’s. In figuur 4 zie je een vereenvoudigde weergave van hoe deze architectuur werkt: informatie stroomt van links naar rechts, waarbij tokens in parallelle lagen worden verwerkt via self-attention-mechanismen. Dit stelt het model in staat om binnen een enkele prompt verbanden te leggen tussen woorden, ongeacht hun positie in de zin.
Deze opbouw maakt transformers bijzonder geschikt voor het genereren van tekst, code, audio of beeld, en vormt de basis voor modellen zoals GPT, Claude en Gemini.
Bronnen en aanvullende lectuur:
Tijdens de trainingsfase van een LLM worden de parameters van het model continu aangepast op basis van de embeddings die als input worden aangeboden. Dit proces herhaalt zich totdat de volledige trainingsdataset is doorlopen. In elke laag van het neurale netwerk worden berekeningen uitgevoerd. Afhankelijk van de functie van die laag kan informatie worden teruggegeven aan voorgaande lagen, of wordt output doorgegeven aan de volgende laag. Door deze propagation wordt de weging van elke parameter in het model aangepast.
Bij grotere modellen kan het gaan om miljarden parameters, waardoor het trainen van dit soort modellen met datasets van triljoenen tokens extreem veel rekenkracht vraagt.
Het model bepaalt zijn nauwkeurigheid via een zogeheten loss function – een wiskundige functie die aangeeft hoe groot het verschil is tussen de voorspelde output en de verwachte output (bron). Oftewel: je kunt voorspellen hoe goed het model op dat moment is in het raden van het juiste volgende token.
Stel dat het model getraind is met de zin “This is a string of reworded tokens”, dan zal de loss function bijvoorbeeld het model vragen om “This is a string of reworded” aan te vullen. Als de output “tokens” is, dan is het foutenpercentage 0. Elke andere uitkomst krijgt een score die aangeeft hoe “verkeerd” de gok was. Hoe verder de score van 0 ligt, hoe groter het verlies – en hoe meer bijsturing nodig is. Dat kan betekenen dat het model nog een extra trainingsronde op dezelfde data nodig heeft, of dat er meer data aan de trainingsset moet worden toegevoegd.
Ideaal gezien nadert het model een score van 0, maar mag het die nooit exact bereiken. Een score van 0 zou namelijk duiden op overfitting – een veelvoorkomend probleem waarbij het model perfect presteert op de trainingsdata, maar vervolgens slecht scoort op echte, nieuwe data (bron).
Overfitting geeft een vals gevoel van betrouwbaarheid en is dus iets dat actief vermeden moet worden.
De pre-training van een LLM bestaat uit meerdere belangrijke stappen. Denk aan het verzamelen en voorbereiden van trainingsdata door ongewenste content eruit te filteren, en het ontwerpen van een geschikte architectuur voor het neurale netwerk die goede prestaties én gewenste eigenschappen oplevert. Dit proces vereist meerdere iteraties, het finetunen van hyperparameters en het meten van de loss function om te controleren of het getrainde model ook goed presteert op echte data.
10 maart 2025 | Blog

10 maart 2025 | Blog

4 december 2025
