

SOC, SIEM, XDR, MDR, EDR… quelles différences ?
3 avril 2023

Face à une menace en perpétuelle évolution, notre CyberSOC doit adapter régulièrement ses mécanismes de défense. Que ce soit via l’amélioration des règles existantes ou bien grâce à la création de nouveaux scénarios, il est impératif de faire vivre nos outils de détection. Cette mission est réalisée par notre Use Case Factory, notre unité spécialisée dans la production de contenus et l’amélioration continue.
Lors du traitement de nombreux incidents de sécurité, nous constatons très souvent la présence de « random strings » dans les artefacts. Il peut s’agir de noms de processus, de chemins d’accès, de clefs de registres, etc. Nous trouvons des valeurs aléatoires dans de nombreuses sources de données et elles sont bien souvent associées à une activité malveillante.

Source : Sandbox Orange Cyberdefense P2A
Au sein du CyberSOC, il est important de pouvoir identifier ces valeurs de façon automatique grâce à nos outils de détection. L’objectif étant de construire des scénarios autour de ces anomalies et ainsi de détecter des menaces dans un environnement contraint : nos SIEM. Pour cela, nous devons construire un mécanisme qui impacte le moins possible leurs performances, tout en obtenant des résultats probants.
Dans cet article, nous allons présenter :
Via une simple recherche sur Internet, nous trouvons de nombreux projets, sur GitHub notamment, qui couvrent ce besoin. S’ils semblent intéressants, nous avons fait le choix de ne pas les utiliser, et ce, pour plusieurs raisons :
Il nous semble donc plus judicieux de développer notre propre outil. Pour cela, nous allons utiliser un jeu de données issues de notre environnement de recherche. Ces jeux de données contiennent plus de 600 entrées, majoritairement des noms de processus mais aussi quelques noms de fichiers. Ils contiennent également une cinquantaine de noms aléatoires identifiés manuellement.

Nous pouvons remarquer une forte récurrence de lettres peu courantes tels que W ou Z. De même, nous voyons des bigrams (séquences de 2 lettres) étonnants tels que WX, ou XK. Ce n’est pas visible dans l’exemple ci-dessus, mais nous pouvons aussi remarquer un usage plus important de caractères non-alpha ainsi qu’une utilisation plus importante des majuscules.
L’analyse de la fréquence des lettres est une technique employée en cryptanalyse, notamment pour décoder des messages chiffrés par substitution de caractères (chiffrement de César). Elle part du postulat que dans le langage courant, certaines lettres sont plus utilisées que d’autres.
Le graphique ci-dessous illustre la fréquence d’utilisation des lettres dans les mots courants, les noms de processus légitimes, mis en perspective avec des valeurs aléatoires.
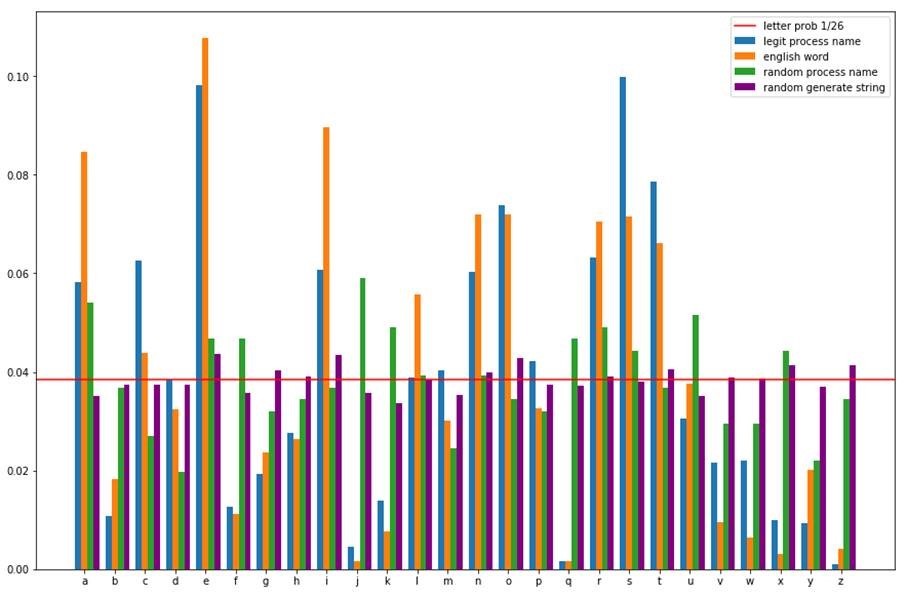
Source : Orange Cyberdefense, CyberSOC
Nous constatons que les fréquences sont beaucoup plus homogènes pour les chaînes aléatoires. A contrario, la distribution est très différente pour les chaînes non aléatoires. Certains caractères sont très employés et d’autres très peu. La présence de lettres rares telles que ‘q’ ou ‘z’, peut donc être utilisée comme marqueur.
Si cette caractéristique est intéressante, elle ne suffit pas. Il faut cependant associer d’autres marqueurs pour s’assurer du caractère aléatoire d’un mot. Pour cela, nous pouvons utiliser les bigrams. Cette étude démontre que certains bigrams (JQ, QG, QK, QY, QZ, WQ et WZ) n’apparaissent pas dans les mots de la langue anglaise. A contrario, certains bigrams tels que TH ou HE sont très courants. Nous pouvons donc également l’utiliser comme marqueur. Pour cela, nous allons utiliser TF-IDF (Term Frequency – Inverse Document Frequency). Nous allons cependant adapter le calcul afin d’accroître le point des valeurs rares.
A l’aide des noms de processus légitimes couplés à une liste aléatoire de mots de la langue anglaise, nous allons créer deux matrices : une pour les lettres et une pour les bigrams. Elles seront ensuite utilisées pour scorer une chaîne de caractères. Plus le score est élevé, plus le mot est aléatoire.
Dans notre étude, nous avons étudié d’autres caractéristiques telles que la fréquence des voyelles, le ratio caractère-majuscule, caractère-minuscule, caractère-alpha ainsi que le ratio caractère-non-alpha. A l’aide d’un algorithme d’apprentissage supervisé basé sur des arbres de décisions, nous allons identifier les caractéristiques les plus déterminantes.
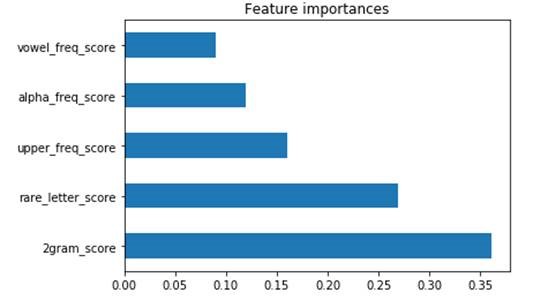
Source : Orange Cyberdefense, CyberSOC
Comme le démontre le graphique ci-dessus, les bigrams et les lettres rares sont les deux caractéristiques les plus déterminantes pour identifier une chaîne aléatoire. Nous allons conserver uniquement ceux-ci et utiliser upper_freq pour pondérer le résultat.
Maintenant que nous avons identifié les variables permettant de discriminer un mot aléatoire et une méthode de détection, nous pouvons construire un prototype. Au vu des résultats obtenus durant les analyses précédentes, des seuils sont configurés et la fonction est appliquée à notre jeu de données.
Enfin, nous comparons les résultats obtenus par notre prototype avec les labels que nous avons associés à chaque valeur. Notre jeu de données contient deux labels : « BAD » pour les chaînes aléatoires, « LEGIT » pour les autres. Notre prototype propose également une catégorie « SUSPICIOUS » pour les chaînes difficiles à classer.
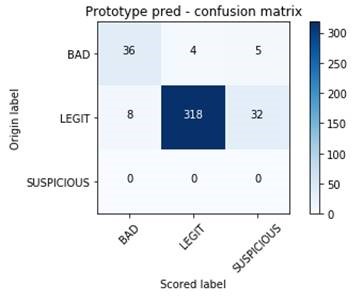
Source : Orange Cyberdefense, CyberSOC
Le résultat est plutôt satisfaisant, le jeu de données contient 403 chaînes dont 45 aléatoires. 36 d’entre elles ont été correctement identifiées et une grande partie des chaînes non aléatoires a été correctement détectée. Nous avons seulement 8 faux-positifs et 4 faux-négatifs.
En s’intéressant aux erreurs, nous remarquons par exemple que :
Les erreurs peuvent être réduites de différentes manières :
Le jeu de données n’étant pas très riche, le prototype a également été testé sur un jeu de données artificielles. S’il y a eu quelques erreurs, globalement les résultats sont plutôt bons (plus de 90% de vrais-positifs et de faux-négatifs). Le prototype peut donc être considéré comme fonctionnel.
L’étape suivante est d’intégrer ce mécanisme à nos SIEM. Le prototype est donc porté dans une app Splunk®. L’impact sur les performances est anecdotique. La version SIEM intègre également de nouvelles fonctionnalités comme la possibilité de retourner un score à la place d’une classe. Elle permet également de générer une matrice de scores pour les différentes caractéristiques. Cela permet de pouvoir mettre en place un mécanisme de scoring différent directement dans le SIEM ou bien d’alimenter un algorithme de machine learning.
Cette application est ensuite utilisée pour développer de nouveaux mécanismes de détection. Dans l’exemple ci-dessous, nous cherchons à identifier les processus ayant un nom aléatoire. Comme évoqué précédemment, nous pouvons intégrer la prévalence du processus (c’est à dire le nombre de machines sur lequel il est exécuté) à notre mécanisme de scoring. Cela permet de réduire le taux de faux-positifs avec une matrice de scoring plus faible. A noter également qu’il est possible de coupler ce mécanisme à une liste blanche.
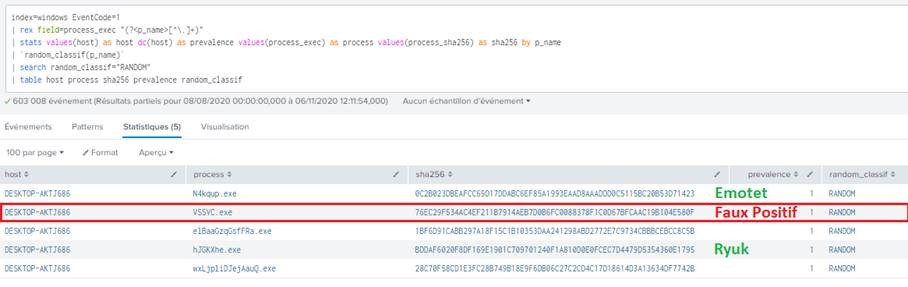
Source : Orange Cyberdefense, CyberSOC
Le résultat démontre que la commande permet bien d’identifier les processus ayant un nom aléatoire et dans notre cas de détecter une menace.
Le cas présenté illustre bien la nécessité de toujours devoir faire évoluer les outils de détection. A partir de cette simple application, de nombreux nouveaux scénarios peuvent être mis en place. Les processus aléatoires ne sont qu’un exemple parmi tant d’autres (clefs de registre, noms de fichiers, url, etc.). Ils peuvent aussi être utilisés pour des scénarios « métiers » comme par exemple le fait de détecter la création de noms d’utilisateurs aléatoires sur une application web.
A noter qu’un nom aléatoire n’est pas systématiquement lié à une menace. En revanche, il est pertinent d’utiliser ce mécanisme en complément d’autres indicateurs tels que la Threat Intelligence où la prévalence permet d’enrichir la détection, et ce, à moindres coûts.
Pour découvrir nos offres SOC et CyberSOC, cliquez ici.

